Process Mining 1: Intro

매 10 분 마다 새롭게 생성되는 데이터의 양은 2003년까지의 모든 데이터를 합한 것보다 더 많다고 한다. 이 데이터 속에는 무궁무진한 가치가 있다고 하여 어떤 사람들은 데이터를 기름이라 비유하기도 한다.
Data Science and Big Data
우리가 들고 다니는 핸드폰에는 14개 이상의 센서가 달려있는데, 이렇게 다양한 이벤트로부터 데이터가 무수히 많이 발생하는걸 볼 수 있다. Internet of Events 시대다.
Internet of Events 에는 크게 4개의 source 가 있는데
(1) Internet of Content (e.g Google, Wiki)
(2) Internet of People (e.g Twitter, Facebook)
(3) Internet of Things (e.g home appliances)
(4) Internet of Places (e.g Smart phones)
왜 이렇게 데이터가 많이 증가할까? 데이터를 만드는 도구들이 널리 퍼졌기도 하지만 기본적으로 디바이스들이 어마어마하게 좋아졌기 때문이다. (가격도 물론).
매 2년마다 같은 범위에 집약할 수 있는 트랜지스터가 2배씩 늘어난다는 무어의 법칙을 일상생활에 적용하면 어떻게 될까? 40년전에는 비행기로 7시간 걸리던 거리가, 매 2년마다 1/2씩 줄어든다면 24 milliseconds 가 된다. 이건 정말 어마어마하게 줄어든 것이다.
이렇게 디바이스들의 처리, 저장 능력이 급속도로 늘었기 때문에 사람들은 이제 Big Data 를 이야기 하게 되었다. 그리고 문제는 여전히
How to extract real value from big data?
기존의 데이터에 비해서 Big data 가 다른점은 무엇일까? 사람들은 빅데이터에 대해 이야기 할때 4V 를 말하곤 하는데
(1) Variety: Different froms of data sources
(2) Veracity: Uncertainty of data
(3) Volumn: Data size
(4) Velocity: Speed of change
Veracity 가 묻고자 하는것은 이런 것들이다. “다량의 면도기 사용 데이터를 수집했는데, 이 면도기를 사용한 사람이, 실제로 그 면도기를 구매한 사람인가?”
이런 성격을 가진 빅데이터를 포함해서 일반적인 데이터를 분석할때 데이터 사이언티스트가 하는 4가지 질문이 있다.
- What happened?
- Why did it happen?
- What will happen?
- What is the best that can happen?
예를 들어 병원에서는 “왜 이 환자가 이렇게 오래 기다렸나?”, “의사가 가이드라인을 따랐나?”, “그럼 대기 시간을 예측할 수 있을까?”, “내일은 얼마나 많은 스태프가 더 필요할까?”, “비용을 얼마나 줄일 수 있을까?” 와 같은 질문을 할 수 있다.
이런 질문에 답하기 위해 다양한 스킬을 이용할 수 있다.
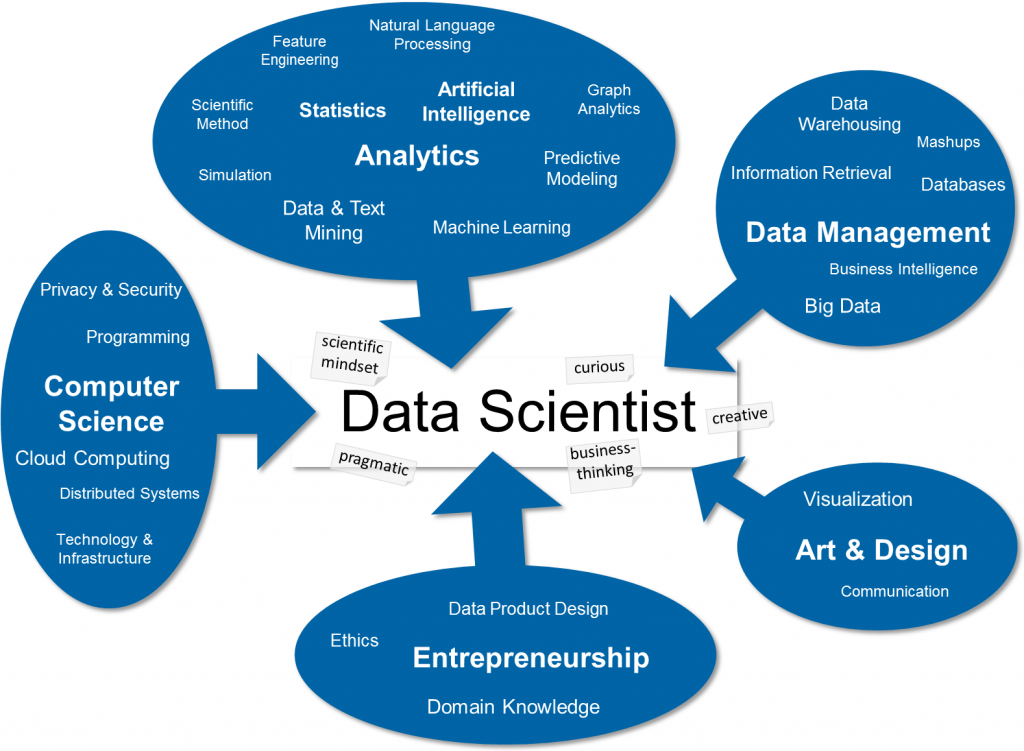
(http://blog.zhaw.ch/datascience)
지금까지 빅데이터에 대해 했지만 이 강의에서는 특별히 process 에 집중한다. 이유는
In the end, It is the process that matters (and no the data or the software)
Not just patterns and decisions, but end-to-end processes
간단히 말하면 프로세스 마이닝은 process-centric view on data science 라 할 수 있다.
즉 프로세스 마이닝은 event data 와 processes, process models 간의 관계를 파악하는 것이다. 어떤 사람들은 Business process intelligence 라 부르기도 한다.
프로세스 마이닝의 use cases 는
- What is the process that people really follow?
- Where are the bottlenecks in my process?
- Where do people (or machines) deiate from the expected or idealized processes?
결국 프로세스 마이닝은 Data science in Action 이다.
Not just data processes matter
Difference Types of Process Mining
프로세스 마이닝의 포지션은 process model analysis 와 data-oriented analysis 의 중간이다.

기존의 데이터마이닝은 데이터만을 보고 프로세스에 집중하지 않았다면, 프로세스 마이닝은 end-to-end 를 포함한 프로세스 자체에 집중한다.
왜 이런 프로세스에 집중할까? 그 이유는 performance-oriented questions, comliance-oriented questions 에 답하기 위해서다.
프로세스 마이닝의 시작은 event data 를 분석하는 것 부터다. event log 는 3가지 컬럼을 기본적으로 가지고 있는데 case id, activity name, time stamp 다.

model 과 event data 사이에는 3가지 관계가 있다.
(1) Play-Out: 단순히 model 을 simulation 하면 다양한 시나리오 (event logs) 를 만들 수 있다.
(2) Play-In: 다양한 event logs 로 부터 model 을 추론하는 것이다. (No modeling is needed)
(3) Replay: event data 를 model 에서 재현함으로써 어떤 요소가 부족한지, 혹은 병목 지점등을 파악할 수 있다. (conformance checking)
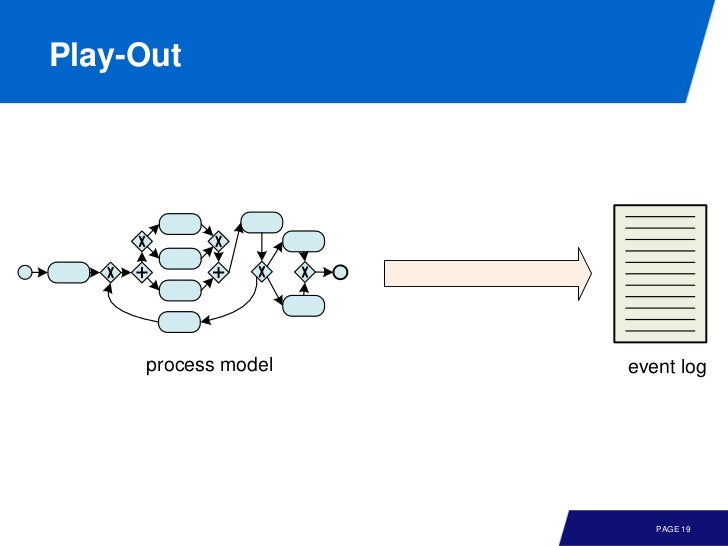
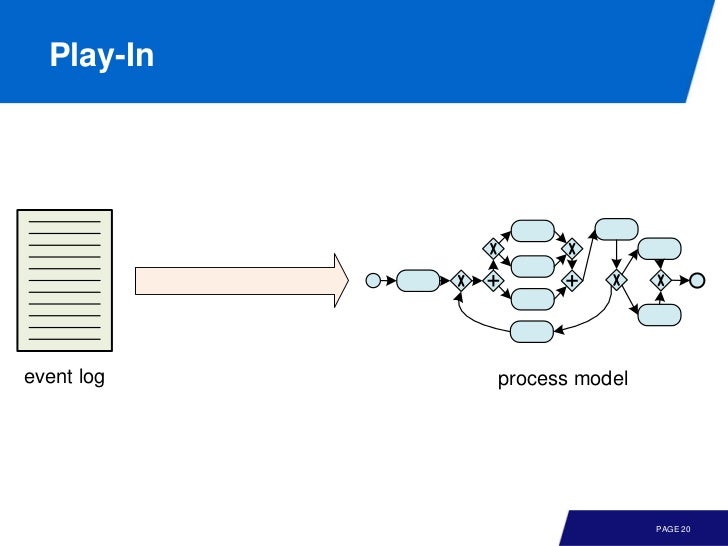
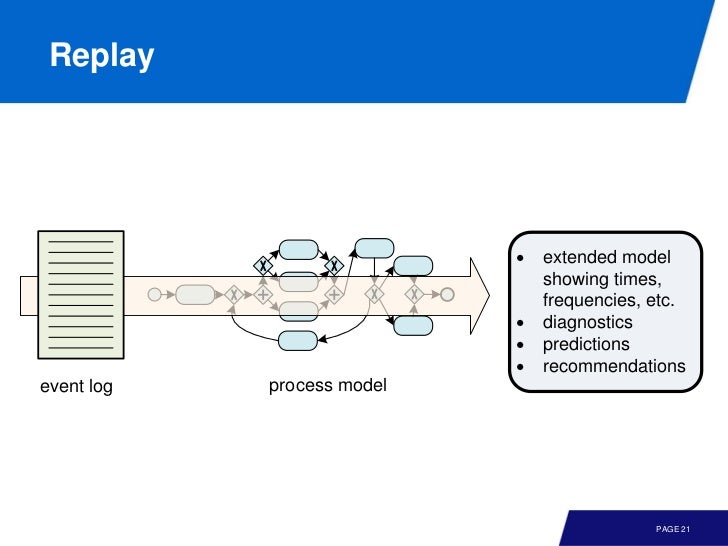
play-in 은 좀 신선하다. 단순히 event logs 만으로 실제로 사람들이 따르는 프로세스를 추론할 수 있다는 이야기다.
그리고 이런 모델에 대해 real data 를 repaly 함으로써 병목 지점을 발견하여 개선함으로써 performance 를 늘릴 수 있다는 것이다.
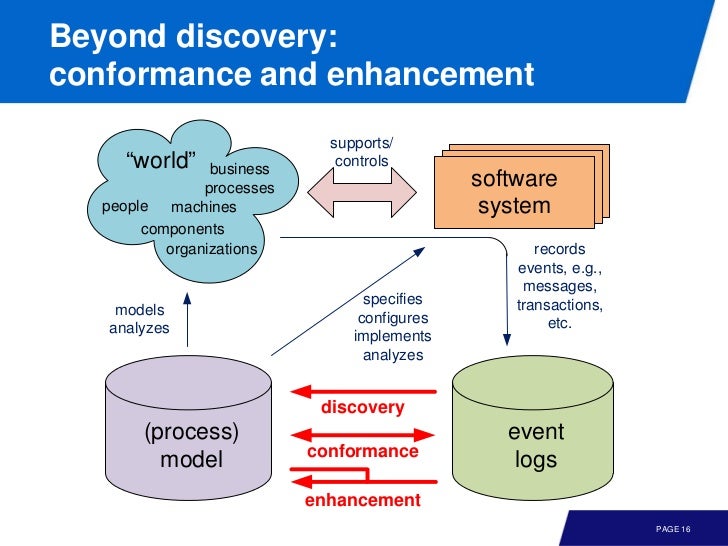
요약하자면 event logs 로 부터 play-in 을 통해 model 을 이끌어 내고 여기에 대해 replay 를 통해 conformance checking 을 할 수 있다. 그리고 enchanced model 을 실제 적용하는 과정이 play-out 이라 볼 수 있다.
How process Mining Relates to Data Mining

기존의 BI 는 실제 reality 를 단순히 KPI 를 요약하는데 그쳤었다. 그러나 anscombe’s quartet 를 보면 알 수 있듯이 똑같은 통계치를 가졌더라도 시각화 하면 전혀 다른 양상일 수 있다.

(http://en.wikipedia.org/wiki/Anscombe's_quartet)
따라서 event data 를 단순히 값으로 요약하는건 reality 를 반영하지 못할 수도 있다. 값도 중요하지만 process 를 봐야한다.
더 깊이 들어가기전에 데이터마이닝에 대해서 좀 알고 가자.
Variables
두 타입의 variable 이 있는데
(1) categorical variables: ordinal, nominal
(2) numerical varaibles: ordered, cannot be enumerated easily
yes / no 같은건 nominal 이다.
Supervised Learning
supervised learning 의 목표는 labeled data 를 이용하여
Explain response variable (dependent variable) in terms of predictor variable (independent variables)
여기에는 크게 나누면 두 가지 테크닉이 쓰인다. 하나는 categorial response variable 에 대해 사용하는 classification 이고 다른 하나는 numerical response variable 에 대해 쓸 수 있는 regression 이다.
Unsupervised Learning
unsupervised learning 은 unlabeled data 를 가지고 clustering 이나 pattern discovert 등을 하는 것이다.
k-means, agglomerative hierarchical, association rules 등 다양한 알고리즘을 이용한다.
Process Mining vs Data Mining
- 둘 다 데이터로부터 시작한다.
- 데이터마이닝은 process-centric 이 아니다.
- process discovery, conformance checking, bottleneck analysis 는 전통적인 데이터마이닝으로 풀기 어렵다.
- 프로세스 마이닝은 end-to-end process models, concurrency 중심이다.
- 프로세스 마이닝의 event log 는 timestamp 와 case 컬럼이 있다.
- 프로세스 마이닝과 데이터마이닝은 복잡한 문제를 풀기 위해 같이 사용될 수 있다.
Learning Decision Tree
decision tree 는 supervised learning 에서 사용되는 기법이다. decision tree 에 놓여있는 아이디어는 처음의 *high entropy (uncertain) 상태에서 attribute 에 따라 subset 으로 쪼개면서 복잡도를 낮춤으로써 low entropy 를 만들 수 있다.
entropy 는 degree of uncertainty, inverse of compressibility 다. 만약 데이터에서 entropy 가 매우 적다면 데이터를 압축할 수 있다. 그러나 대부분의 경우 high entropy 이기 때문에
Goal: reduce entropy in leaves of tree to improve predictability
엔트로피를 계산하기 위해 로그를 이용하면
intuition 은 초록공과 빨간공이 1:1 로 섞여있을땐 E = 1 이고, 빨간공이나 초록공만 있을때는 E = 0 이다. 따라서 decision tree 가 깊어지면 깊어질수록 전체 E 가 낮아진다.
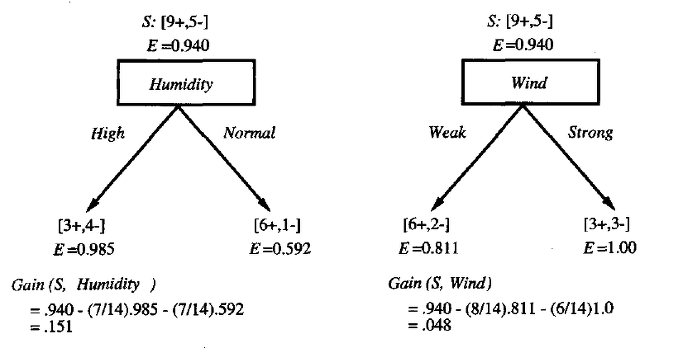
(http://frontjang.tistory.com)
그리고 이렇게 얻어진 overall entropy 의 차이를 information gain 이라 부른다. classification 에는 변화가 없어도 information gain 이 있을 수 있다. 반대로 한단계 더 분리 되었어도 information gain 이 0 일 수 있다.
따라서 선택 가능한 모든 attribute 에 대해 information gain 을 비교하여 가장 큰 attribute 를 선택하고 더 이상의 커다란 변화가 없을때 까지 반복하면 decision tree 를 만들 수 있다.
minimal gain, maximum depth 등을 세팅할 수도 있고, overfitting (모든 경우를 다 분리하는것) 을 막기 위해 최소 노드 사이즈를 정할 수 있다. post pruning 등 다양한 기술이 있다.
프로세스 마이닝에 적용해 보면 모델에서 분기 될 때 “What is driving these decisions?”, 등을 파악할 수 있고 “most likely path” 같은 문제도 해결할 수 있다.
Association Rule
unsupervised learning 도구인 association rule 을 이용해 패턴을 찾아보자.
association rule 은 X => Y 형태다. 시작 전에 몇가지 개념을 보고 넘어가자.
Support
support 는 0 ~ 1 사이의 값을 가지는데, 1 이면 good, 0 로 갈수록 bad 를 의미한다.
즉 전체 데이터 중 X, Y 가 같이 있는 instance 의 비율을 의미한다.
Confidence
support 와 마찬가지로 0 ~ 1 값을 가지며 높은 값일수록 더 연관성 있음을 의미한다.
전체 X 인스턴스 중 X, Y 가 같이 있는 instance 의 비율을 의미한다.
Lift
lift 는 실제 같이 나타나는 비율 / 기대했던 비율 이다. 식을 보면 알겠지만 각 아이템이 나타나는 비율을 독립이라 가정한 것을 분모로 실제 나타나는 비율을 나눈 것이다. 따라서 lift > 1 이면 X 는 Y 가 나타나는데 긍정적인 영향을 미치거나 혹은 Y 가 X 에 대해 긍정적인 영향을 미친것이다. 반면 lift < 1 이면 반대고, lift = 1 이면 서로 관계가 없다 볼 수 있다.
여기를 인용하면
A lift value greater than 1 indicates that X and Y appear more often together than expected; this means that the occurrence of X has a positive effect on the occurrence of Y or that X is positively correlated with Y.
A lift smaller than 1 indicates that X and Y appear less often together than expected, this means that the occurrence of X has a negative effect on the occurrence of Y or that X is negatively correlated with Y
A lift value near 1 indicates that X and Y appear almost as often together as expected; this means that the occurrence of X has almost no effect on the occurrence of Y or that X and Y have Zero Correlation.
class 가 많으면 rule 또한 엄청나게 많아지기 때문에 support, confidence, lift 를 이용해서 룰을 필터링하거나 정렬할 수 있다.
일반적으로 이 3가지에 대해
(1) support 는 높을수록 좋다.
(2) confidence 는 1에 가까워야 한다.
(3) lift 는 1보다 커야한다.
다음의 조건이 있을때 각 룰에 대해 support, confidence, lift 를 계산해 보자.
100 customers buy diapers and / or beer:
- 9 customers buy just Hoegaarden
- 40 customers buy just Pampers
- 50 customers buy just Pampers and Dommelsch
- 1 customer buys just Pampers, Hoegaarden and Dommelsch
먼저 {Pampers} => {Dommelsch} 는
s = 51 / 100 = 0.51, c = 51 / 91 = 0.56, l = 51 * 100 / (91 * 51) = 1.1
다음으로 {Dommelsch} => {Pampers} 는
s = 0.51, c = 1, l = 1.1 이다.
값을 보면 이 두 가지 룰은 상당히 신빙성이 있다고 볼 수 있다. 그리고 나머지 룰들을 살펴봐도 supoort, confidence, lift 값 이 상당히 낮다.
계산 방법은 간단한데, class 가 많으면 계산해야 할 rule 자체가 어마어마하게 많아진다. 이 문제를 해결하기 위해 몇 가지 방법이 있다.
Apriori Algorithm
X 의 부분집합인 Y 에 대해서, X 의 support 가 높으면 X 의 부분집합도 충분히 빈번해야 한다. 그래서 X 의 부분집합인 Y 의 support 가 낮으면 Y 의 부분집합을 살펴볼 필요가 없어 연산 수를 줄일 수 있다.
Pattern Mining
여기서 본 연관 분석은 process 를 고려하지 않지만, 이 기법을 잘 활용하면 sequence mining 이나 episode mining 등등에 활용 될 수 있다.
Cluster Analysis
unsupervised learning 기법인 clustering 도 간단히 살펴보자.

(http://en.wikipedia.org/wiki/Cluster_analysis)
k-means clustering
여기서 k 는 몇개의 집단으로 나눌건지를 의미하는 숫자다. 알고리즘 자체는 굉장히 직관적이다.
(1) 먼저 centroid 라 부르는 점들을 attribute 에 랜덤하게 혹은 레귤러 하게 k 개 배치한다.
(2) 각 점에서 centroid 까지 거리가 가장 짧은 centroid 를 선택하고, 이 집단 내부에서 가운데 점을 계산해 centroid 로 다시 정한다.
(3) centroid 에 변화가 없을 때 까지 계속 반복한다.

(http://datavisualization.blog.com)
// ref: http://datavisualization.blog.com/visible-data/cluster-analysis/
Select K points as the initial Centroids
REPEAT
Form K clusters by assigning all points to the closest Centroid
recompute the Centroid for each cluster
UNTIL Centroids don’t change // or less than thresahold”
초기에 centroid 가 랜덤하게 선택되기 때문에 non-deterministic 이어서 여러번 계산 후에 가장 좋은 clustering 을 골라야 한다.
그리고 k 값에 따라 클러스터가 달라질 수 있으므로 변화시켜가면서 좋은 k 값을 찾아야 한다.

(http://datavisualization.blog.com)
Agglomerative hierarchical clustring
k-means 이외에도 다양한 클러스터링 알고리즘이 있다.

Applying Process Mining
클러스터링은 event-log 를 분할하는데 쓸 수 있다. 그러면 특징이 다른 event-log 를 뽑아낼 수 있고 각각의 클러스터에 대해 모델을 만드는데 유용하다.
Evaluating Mining Result
마이닝으로 모델을 만들거나, 결과를 얻었다고 하자. 어떻게 평가할까?
Confusion Matrix
confusion matrix 는 predict class 와 actual class 를 기반으로 테이블을 만든 것이다.

여기에 대해 error, accuracy, precision, recall, F1-score 등을 계산할 수 있다.

(http://www.slideshare.net/salahecom/08-classbasic)
Cross Validation
가지고 있는 데이터로 모델을 만들면, 모델에는 잘 맞지만 실제 데이터에는 안맞을 수 있다.
Overfitting : the model is too specific for the data set used to learn the model and performs poorly on new instances
Underfitting : the model is too general and does not exploit the data
그래서 데이터셋을 training set 과 test set 으로 분리해서 각각 훈련, 퍼포먼스 테스트를 위해 사용한다.
Summary
이번 주차엔 데이터마이닝에 대해서 논했는데, 다음 시간부터는 process discovery, conformance checking 등에 대해 이야기 한다. 어째 오토마타의 향연이 될 것 같기도
References
(1) Process Mining: Data science in Action by Wil van der Aalst
(2) www.processmining.org
(3) http://blog.zhaw.ch/datascience/the-data-science-skill-set/
(4) http://fluxicon.com/blog
(5) Process Mining Chapter 1
(6) Anscombe’s quartet
(7) http://frontjang.tistory.com
(8) http://analyticstrainings.com/?p=151
(9) http://datavisualization.blog.com
(10) http://www.cs.umd.edu
(11) http://crsouza.blogspot.kr
(12) http://www.slideshare.net/salahecom/08-classbasic
comments powered by Disqus