Functional Programming 5
지난주엔 Scala 가 리스코프 치환 원칙 을 지키기 위해 어떻게 Variance(공변성) 을 문법적으로 지원하는지 알아보았다. 직접 List 컨테이너를 구현해 보면서 함수의 인자는 Covariant, 리턴타입은 Contravariant 란 것도 알게 되었고, Nil 을 만들기 위해 Nothing 을 어떻게 엮을 수 있는지도 직접 확인해 보았다. 마지막으로, 프로그래머가 가장 많이 작성하는 로직인 Decomposition 을 Pattern Matching 을 이용해 더 우아하게 작성하는법도 배웠다. 오오 추상화 오오
이번시간에도 List 를 가지고 놀면서 Reduce 의 개념과 Scala 의 Implicit 키워드가 어떤 역할을 하는지 배워본다.
More Functions on Lists
List.last 는 마지막 원소를 돌려준다. head 나 tail 같은 경우는 상수 시간 내에 리턴되지만, last 는 어떨까?
def last[T](l: List[T]): T = xs match {
case List() => throw new Error('last of empty list')
case List(x) => x
case y :: ys => last(ys)
}
그러므로 길이 n 에 비례하는 성능을 보여준다.
lasttakes steps proportional to the length of the list
마찬가지로 마지막 원소를 제외하고 나머지를 돌려주는 Last.init 경우도 같은 성능을 보여준다. 이렇게 구현할 수 있다.
def init[T](xs: List[T]): List[T] = xs match {
case List() => throw new Error("init of empty list")
case List(x) => List()
case y :: ys => y :: init(ys)
}
concat 은 어떨까? xs 를 받아서 ys 앞에 붙이는 함수다. prepend 함수라 보면 되겠는데, 지난 시간에 논의했었던 ::: 랑 같다.
지난 시간에 언급 했듯이 xs ::: ys 처럼 : 로 끝나는 연산자는 우측에 오는것이 실제 좌측 피연산자다. ys .::: (xs) 와 같다.
def concat[T](xs: List[T], ys: List[T]): List[T] = xs match {
case List() => ys
case z :: zs => z :: concat(zs, ys)
}
이 , reverse 를 구현 해 보자.
def reverse[T](xs: List[T]): List[T] = xs match {
case List() => xs
case y :: ys => reverse(ys) ++ List(y)
}
reverse 도 마찬가지로 길이 n 에 quadratic 한 성능을 보여준다. 이는 reverse 내부에서 ++ 을 사용하기 때문이다. 이는 더 개선할 수 있는데, 후에 논의하겠다.
참고로, ++ 와 ::: 는 하는일은 같으나, ::: 는 List 에만 적용 가능하고 ++ 는 다른 Traversal 에도 적용 가능하다. 여기 참조
이제 removeAt 을 구현 해 보자.
def removeAt[T](n: Int, xs: List[T]): List[T] =
(xs take n) ::: (xs drop n + 1)
flatten 은 다음과 같이 작성할 수 있다.
def flatten(xs: List[Any]): List[Any] = xs match {
case List() => xs
case List(y :: ys) => y :: flatten(ys)
case y :: ys => y :: flatten(ys)
}
Pairs and Tuples
(3, "example") 과 같은 형태를 Pair 라 부르는데, 이건 사실 Tuple 의 특별한 형태다.
(T1, ..., Tn) 은 scala.Tuplen[T1, ..., Tn] 의 parameterized type 이고, expression (e1, ..., en) 은 사실 scala.Tuplen(e1, ..., en) 과 동일하다.
그리고 tuple 의 패턴 (p1, ..., pn) 은 constructor pattern scala.Tuplen(p1, ..., pn) 과 같다. TupleN 클래스를 구경 해 보자.
case class Tuple2[T1, T2](_: +T1, _2: +T2) {
override def toString = "(" + _1 + "," + _2 + ")"
}
멤버를 접근할 때 _1, _2 와 같은 식으로 접근하므로, 패턴 매칭에서
val (label, value) = pair 는 사실 다음과 같다.
val label = pair._1
val value = pair._2
Tuple 의 패턴 매칭을 이용하면, 다음과 같이 중첩된 case 를 사용하는 merge sort 함수를
def msort(xs: List[Int]): List[Int] = {
val n = xs.length / 2
if (n == 0) xs
else {
def merge(xs: List[Int], ys: List[Int]): List[Int] = xs match {
case Nil => ys
case x :: xs1 => ys match {
case Nil => xs
case y :: ys1 => {
if (x > y) y :: merge(xs, ys1)
else x :: merge(xs1, ys)
}
}
}
val (left, right) = xs splitAt n
merge(msort(left), msort(right))
}
}
요로코롬 바꿀 수 있다. 오오 패턴매칭 오오
def msort(xs: List[Int]): List[Int] = {
val n = xs.length / 2
if (n == 0) xs
else {
def merge(xs: List[Int], ys: List[Int]): List[Int] =
(xs, ys) match {
case (xs, Nil) => xs
case (Nil, ys) => ys
case (x :: xs1, y :: ys1) =>
if (x > y) y :: merge(xs, ys1)
else x :: merge(xs1, ys)
}
val (left, right) = xs splitAt n
merge(msort(left), msort(right))
}
}
Implicit Parameters
Int 뿐만 아니라 우리가 만든 msort 함수를 더 범용적으로 활용할 수 있도록, Currying 을 ´용하자.
def msort[T](xs: List[T])(lt: (T, T) => Boolean): List[T] = {
val n = xs.length / 2
if (n == 0) xs
else {
def merge(xs: List[T], ys: List[T]): List[T] =
(xs, ys) match {
case (xs, Nil) => xs
case (Nil, ys) => ys
case (x :: xs1, y :: ys1) =>
if (lt(x, y)) x :: merge(xs1, ys)
else y :: merge(xs, ys1)
}
val (left, right) = xs splitAt n
merge(msort(left)(lt), msort(right)(lt))
}
}
아래는 테스트코드
"msort" should "return an ordered list" in {
val xs = List(4, 2, 7, 1, 11, 9, 3)
val ys = List(10, 9, 8, 7, 6)
assert(msort(xs)((x: Int, y: Int) => x < y) == List(1, 2, 3, 4, 7, 9, 11))
assert(msort(ys)((x: Int, y: Int) => x < y) == List(6, 7, 8, 9, 10))
}
참고로 msort 에 Int 인자를 주는 경우, x: Int, y: Int 처럼 타입을 명시하지 않아도 알아서 xs 를 보고 추론한다.
Parameterization with Ordered
¬실은 scala.math.Othering[T] 에 ordering 을 나타낼 수 있는 클래스가 있다. 이를 활용하면 msort 를 다음과 같이 리팩토링 할 수 있다.
def msort[T](xs: List[T])(ord: Ordering[T]): List[T] = {
val n = xs.length / 2
if (n == 0) xs
else {
def merge(xs: List[T], ys: List[T]): List[T] =
(xs, ys) match {
case (xs, Nil) => xs
case (Nil, ys) => ys
case (x :: xs1, y :: ys1) =>
if (ord.lt(x, y)) x :: merge(xs1, ys)
else y :: merge(xs, ys1)
}
val (left, right) = xs splitAt n
merge(msort(left)(ord), msort(right)(ord))
}
}
테스트 코드는,
"msort" should "return an ordered list" in {
val xs = List(4, 2, 7, 1, 11, 9, 3)
val ys = List(10, 9, 8, 7, 6)
val zs = List("pineapple", "apple", "banana", "watermelon")
assert(msort(xs)(Ordering.Int) == List(1, 2, 3, 4, 7, 9, 11))
assert(msort(ys)(Ordering.Int) == List(6, 7, 8, 9, 10))
assert(msort(zs)(Ordering.String) == List("apple", "banana", "pineapple", "watermelon"))
}
다 좋은데, Ordering.Int 인자 자체를 숨겨버렸으면 좋겠다. msort 의 ord 파라미터를 다음과 같이 변경하자. (implicit ord: Ordering[T])
def msort[T](xs: List[T])(implicit ord: Ordering[T]): List[T] = {
val n = xs.length / 2
if (n == 0) xs
else {
def merge(xs: List[T], ys: List[T]): List[T] =
(xs, ys) match {
case (xs, Nil) => xs
case (Nil, ys) => ys
case (x :: xs1, y :: ys1) =>
if (ord.lt(x, y)) x :: merge(xs1, ys)
else y :: merge(xs, ys1)
}
val (left, right) = xs splitAt n
merge(msort(left), msort(right))
}
}
테스트 코드는 아래와 같다.
"msort" should "return an ordered list" in {
val xs = List(4, 2, 7, 1, 11, 9, 3)
val ys = List(10, 9, 8, 7, 6)
val zs = List("pineapple", "apple", "banana", "watermelon")
assert(msort(xs) == List(1, 2, 3, 4, 7, 9, 11))
assert(msort(ys) == List(6, 7, 8, 9, 10))
assert(msort(zs) == List("apple", "banana", "pineapple", "watermelon"))
}
놀랍게도, 파라미터가 사라져버렸다. ~오오 스칼라 오오~ implicit 하나만 추가했을 뿐인데! implicit 를 파라미터 타입에 추가하면 아래처럼 해석된다.
타입 T 인 implicit 파라미터에 대해서,
(1) implicit 이며
(2) T 와 호환 가능한 타입을 가지고 있고
(3) function call 내에서 찾을 수 있거나
(4) 혹은 T 와 관련된 companion object 내에 있는
single definition (most specific) 이 있는지 컴파일러가 찾는다. 파라미터로 사용하고 아니면, 에러를 뿜는다.
즉 위의 코드의 경우 Ordering[String] 와 Ordering[Int] 는 어딘가에 implicit 로 처리되어 이미 존재한다.
Higher-Order List Functions
List 에 사용하는 메소드들은 종종 반복된 패턴 (recurring patterns) 을 지는데, 3가지로 요약해 보면 아래와 같다.
(1) transformaing each element in a list ina certain way
(2) retrieving a list of all elements satisfying a criterion
(3) combining the elements of a list using an operator
함수형 언어는, higher-order function 이용해서 generic function 을 만들 수 있다.
Map
리스트의 모든 원소에 함수 f 를 적용 (Applying) 하는 고차 함수 (Higher-Order Function) 은 map 이다.
abstract class List[T] {
...
def map[T](f: T => U): List[U] = this match {
case Nil => this
csae x :: xs => f(x) :: xs.map(f)
}
...
}
실제로 map 은 좀 더 복잡한데, tail-recursion 과 다양한 종류의 collection 을 지원하기 위함이다.
Filter
abstract class List[T] {
...
def filter(p: T => Boolean): List[T] = this match {
case Nil => this
case x :: xs => if (p(x)) x :: xs.filter(p) else xs.filter(p)
}
...
}
이외에도 filterNot 과 partition이 있다. partition 은 filter 와 filterNot 의 결과를 둘 다 돌려준다.
takeWhile 은 일치하지 않는 곳에서 filtering 을 멈추고, 그 전까지의 결과를 돌려준다. 반대로 dropWhile 은 takeWhile 에서 취해진 결과 이외의 나머지를 돌려준다.
scala> val zs = List(2, -4, 1, 4, 7)
zs: List[Int] = List(2, -4, 1, 4, 7)
scala> zs partition(x => x > 0)
res38: (List[Int], List[Int]) = (List(2, 1, 4, 7),List(-4))
scala> zs dropWhile(x => x > 0)
res39: List[Int] = List(-4, 1, 4, 7)
scala> zs takeWhile(x => x > 0)
res40: List[Int] = List(2)
scala> zs span(x => x > 0)
res41: (List[Int], List[Int]) = (List(2),List(-4, 1, 4, 7))
takeWhile, dropWhile 을 이용하면 다음과 같은 pack 함수도 만들 수 있다.
def pack[T](xs: List[T]): List[List[T]] = xs match {
case Nil => Nil
case x :: xs1 =>
xs.takeWhile(y => y == x) :: pack(xs.dropWhile(y => y == x))
}
아래는 테스트코드
val ts = List("a", "a", "b", "c", "c", "a")
val ss = List(List("a", "a"), List("b"), List("c", "c"), List("a"))
"pack" should "return a packed list" in {
assert(pack(ts) == ss)
}
Reduction of Lists
reduce 는 리스트의 모든 원소에 특정 연산을 수행해 하나의 결과를 만들어 내고 싶을 때 사용한다.
def sum(xs: List[Int]) = (0 :: xs) reduceLeft((x, y) => x + y)
def product(xs: List[Int]) = (1 :: xs) reduceLeft((x, y) => x * y)
사실 reduceLeft, reduceRight 를 기억하는 쉬운 방법은, 왼쪽으로 / 오른쪽으로 기운 트리 를 기억하는 것이다.
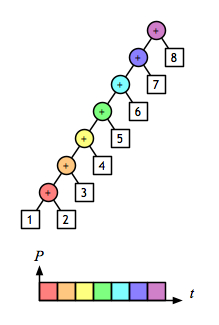
https://joelneely.wordpress.com/
reduce 와 비슷하지만 초기 인자를 받아 empty-list 에 대해서도 호출될 수 있는 fold 가 있다.
abstract class List[T] {
...
def reduceLeft(op (T, T) => T): T = this match {
case Nil => throw new Error("Nil.reduceLeft")
case x :: xs => (xs foldLeft x)(op)
}
def foldLeft[U](z: U)(op: (U, T) => U): U = this match {
case Nil => z
case x :: xs => (xs foldLeft op(z, x))(op)
}
...
}
foldRight 는 오른쪽으로 기운 트리 를 생각하면 된다.
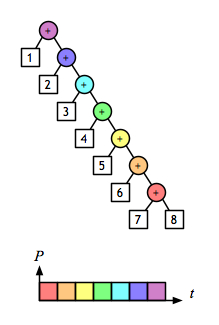
https://joelneely.wordpress.com/
def reduceRight(op: (T, T) => T): T = this match {
case Nil => throw new Error("Nil.reduceRight")
case x :: Nil => x
case x :: xs => op(x, xs.reduceRight(op))
}
def foldRight[U](z: U)(op: (T, U) => U): U = this match {
case Nil => z
case x :: xs => op(x, (xs foldRight z)(op))
}
foldLeft 와 foldRight 는 같은 일을 하긴 하는데, 때때로는 둘 중 하나만 적절한 경우도 있다. 예를 들어
def concat[T](xs: List[T], ys: List[T]): List[T] =
(xs foldRight ys)(_ :: _)
foldRight 대신에 foldLeft 가 오면 어떻게 될까? 타입 에러 가 발생한다. 3 :: List(4) 는 가능해도 List(3) :: 4 는 불가능하기 때문이다.
Reasoning About Concat
We would like to verify that concatenation is associative, and that it admits the empty list
Nilas neutral element to the left and to the right
이번장에서는 natural indction 과 비슷한 structural induction 을 이용해 함수형 프로그래밍에서 어떻게 함수의 정확성을 증명할 수 있는지 배운다.
함수형 프로그래밍에선 side-effect 가 없기 때문에, reduction step 이 전체나, 부분이나 동일하게 적용된다. 이걸 다른말로 참조 투명성 (referential transparency) 라고 부른다. 혹시 몰라 원문을 첨부 하자면,
Note that a proof can freely apply reduction steps as equalities to some part of a term
That works because pure functional programs don’t have side effects so that a term is equivalent to the terms to the term to which it reduces.
This principle is called referential transparency.
Structural Induction
property P(xs) 를 모든 xs 에 대해 증명하기 위해
(1) show that P(Nil) holds (Base case)
(2) for a list xs and some element x, show the induction step:
if P(xs) holds, then P(x :: xs) also holds
우리는 (xs ++ ys) ++ zs = xs ++ (ys ++ zs) 를 증명하고 싶다. 이를 위한 concat 함수는
def concat[T](xs: List[T], ys: List[T]) = xs match {
case List() => ys
case x :: xs1 => x :: concat(xs1, ys)
}
이 concat 의 정의로 부터 두 가지 사실을 뽑아낼 수 있다. (distill two defining clauses)
(1) Nil ++ ys = ys
(2) (x :: xs1) ++ ys = x :: (xs1 ++ ys)
이제 먼저 Base-case 인 Nil 에 대해 먼저 참임을 보이면 된다.
(Nil ++ ys) ++ zs = Nil ++ (ys ++ zs)
좌변은 (1) 에 의해
ys ++ zs이고 우변도 (1) 에 의해ys ++ zs이다.
이제 P(xs) 가 참일때 P(x :: xs) 임을 보이면 된다. 먼저 좌변부터 하면
= ((x :: xs) ++ ys) ++ zs by (2)
= (x :: (xs ++ ys)) ++ zs by (2)
= x :: ((xs ++ ys) ++ zs) by (2)
= x :: (xs ++ (ys ++ zs)) by induction hypothesis (P(xs))
우변을 정리하면,
= (x :: xs) ++ (ys ++ zs) by (2)
= x :: (xs ++ (ys ++ zs))
우변과 좌변이 같으므로, P 는 성립한다.
A Larger Equational Proof on Lists
이제 reverse 의 xs.reverse.reverse = xs 라는 속성을 증명해 보자. 다음 2개의 clause 를 알고 있다. (교수님이, 좀 더 amenable 하기 때문에 비 효율적인 정의를 골랐다고 하심.)
(1) Nil.reverse = Nil
(2) (x :: xs).reverse = xs.reverse ++ List(x)
Base-case 는 패스하고, 바로 x :: xs 에 대한 것 부터 들어가면 좌변은
(x :: xs).reverse.reverse
= (xs.reverse ++ List(x)).reverse
우변은
x :: xs
= x :: xs.reverse.reverse
이걸로는 할 수 있는게 없으므로 xs.reverse 를 ys 라 놓으면
(ys ++ List(x)).reverse = x :: ys.reverse 를 증명하면 된다. Auxiliary Equation 인데, 먼저 Base-case 부터 참임을 보이면
좌변은
(Nil ++ List(x)).reverse
= List(x).reverse // ++ clause 1
= (x :: Nil).reverse // List Definition
= Nll.reverse ++ List(x) // reverse clause 2
= Nil ++ List(x) // reverse clause 1
= x :: Nil // List Definition
우변은
x :: Nil.reverse
= x :: Nil // reverse clause 1
이제 ((y :: ys) ++ List(x)).reverse 와 x :: (y :: ys).reverse 가 같음을 보이면 된다.
((y :: ys) ++ List(x)).reverse
= (y :: (ys ++ List(x)).reverse // ++ clause 2
= (ys ++ List(x)).reverse ++ List(y) // reverse clause 2
= (x :: ys.reverse) ++ List(y) // induction hypothesis
= x :: (ys.reverse ++ List(y) // reverse clause 2
= x :: (y : ys).reverse
이것은 우변 x :: (y :: ys).reverse 와 동일하므로 Auxiliary equation 이 성립하고, 본래의 성질 xs = xs.reverse.reverse 도 성립한다.
Exercise
map 증명하라고 주시는데, 못해먹겠다 -_-; 패쓰!
Summary
Reduction, Fold, referential transparency 그리고 structural induction 에 대해서 배웠다.
References
(1) scala-list-concatenation-vs
2014-10-14, Functional Programming in Scala, Coursera
comments powered by Disqus