Process Mining 5: Decision, Social, Organization Mining
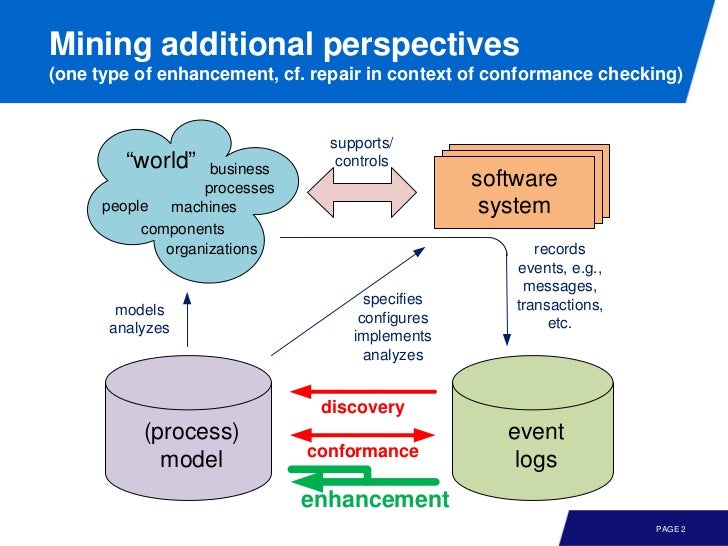
지난 4 주간 배운바를 간단히 정리해보면
- 첫 2주는 model discovery
- 지난 2주는 conformance checking
이 것들은 control flow 에 관련된 것들이었다. 이제는 기본적인 event log 의 데이터 뿐만 아니라 time, resource, data 등을 이용하면서 model enhancement 를 할 수 있는 기법들을 배워보자.
앞으로 이야기 할 내용은
- mining decision points
- mining bottlenecks
- mining social networks
- comparative process mining
- operational support: detect, predict, recommend
Mining Decision Points
model enhancement 은 conformance checking 과는 다르게, 모델을 더 나은 방향으로 변형하는 것을 목표로 한다.
- extend: adding additional perspectives to the model using event data
- repair: improving the quality of the model using event data
먼저 extend 에 대해 이야기 해 보자. decision point 를 마이닝 할 건데, 인풋으로
- event log
- process model
이 필요하다. 그리고 로그와 모델이 aligned 되어 있다는 가정하에 마이닝을 시작한다.
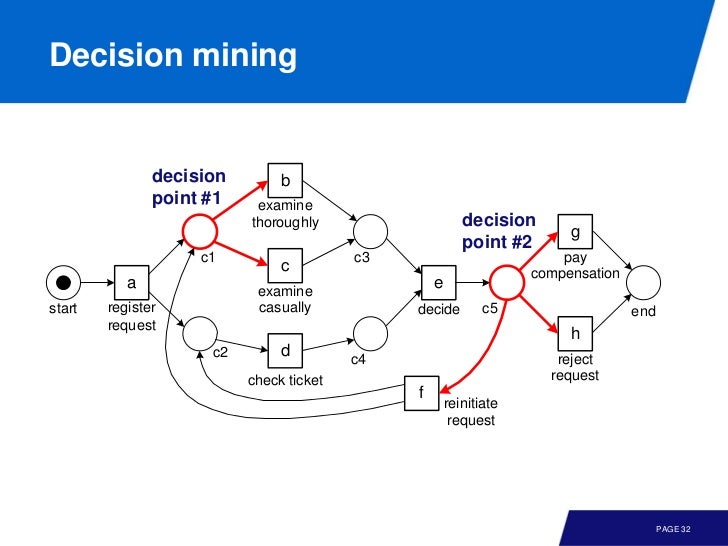
decision tree 에서 했던것 처럼 predictor variable 을 이용해 response variable 인 transition 을 선택할 수 있다. 이 때 predictor variable 은 event log 에 있는 attribute 다. 예를 들어
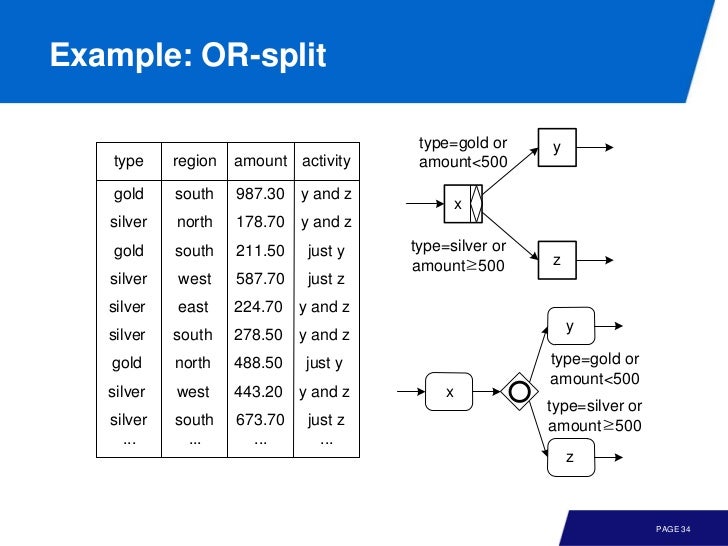
여기서 우측 하단에 inclusive OR 이 있는데, 하나만 택하거나 둘 모두 택할 수 있는 place 다. 이 것도 마찬가지로 decision tree 를 만들듯이 생성할 수 있다. 슬라이드에서는 x, y 로의 두 guard 를 만들었지만 둘다 택 할 수 있는 경우가 있다. 예를 들어 amount < 500, type = silver 면 y, z 모두를 택한다.
event log 에 있는 정보 이외에도, decision point 를 마이닝 하기 위해 predictor variable 로 last event 나 previous event 를 사용할 수 있다.
이외에도 predictor variable 는 프로세스 인스턴스의 context 에 근거해서 다양한 값일 수 있는데
- number of cases running
- number of resources present
- workload of reousrce
- day of the week 등
한 가지 주의할점은 더 많은 변수, 더 많은 조합들이 있을수록 데이터가 희박해지기 때문에 overfitting 할 수 있다는 점이다.
이벤트 로그의 속성을 이용해 만든 decision tree 로, 모델에 guard 를 추가할 수 있다. 하지만, 이 가드가 prescriptive 한 것은 아니다. 오히려 descriptive 에 가깝다.
The guard discovered are describing what has happend rather than what should have happended
Mining Bottlenecks

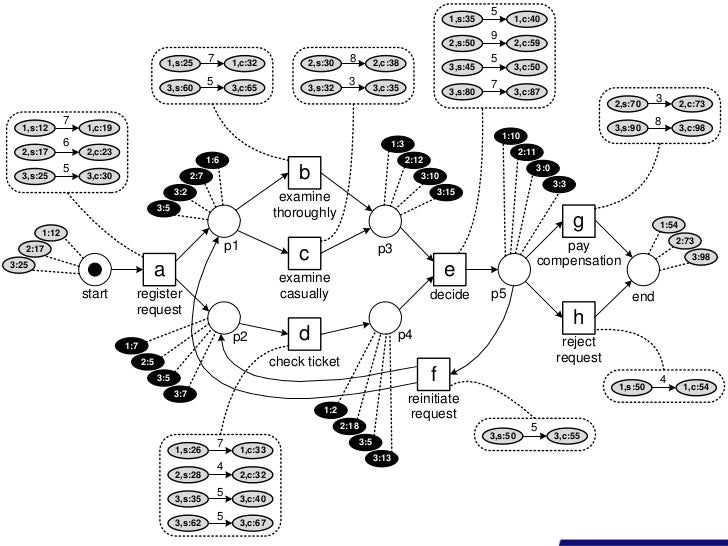
위 로그를 돌려보면, 이와 같은 duration 같은 정보를 얻을 수 있다.


이런식으로 볼 수도 있다.
Mining Social Networks

잘 보면 이벤트로그를 arrtibute name 과 연관 지었다.

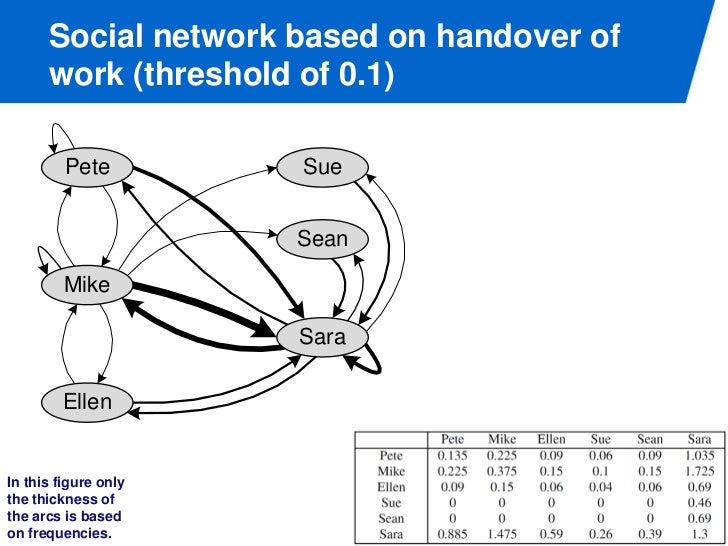
이 로그를 이용하면 누가 무엇을 얼마나 실행했는지 파악할 수 있고, 이를 이용해서 그래프를 그릴 수 있다. 한 가지 생각해 볼 점은 노드가 얼마나 중요한가 는 정의에 따라 다를 수 있다는 것이다. closeness, out degree 등등.
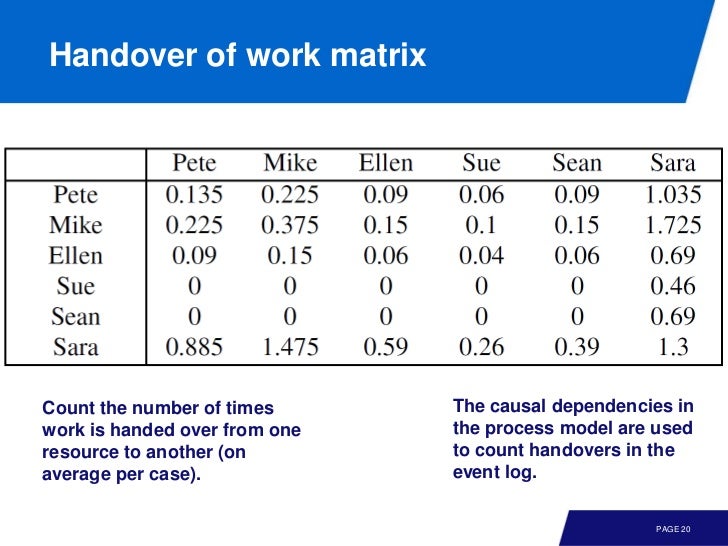
이건 누구로 부터 누구로 일이 전달되었는가를 매트릭스로 표현한 것이다. 이걸 이용하면
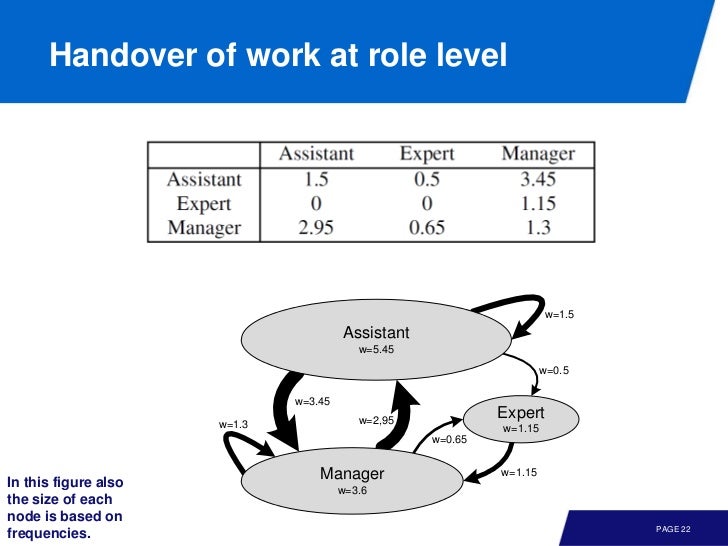
이름이 아니라 다른 attribute 인 role 을 이용하면
소셜 네트워크 마이닝을 위한 기법을 정리하면
- Resource-activity matrix 로 누가 무엇을 하는지
- Handover of work matrix 로 일이 어떻게 전달되는지
를 파악할 수 있고, 이를 이용해 그래프를 만들 수 있다. 물론 이 외에도 다양한 방법들이 있다.
Organizational Mining
클러스터링과 비슷하다고 보면 된다. 이벤트 로그를 기반으로 몇개의 집단으로 묶는 것이다.
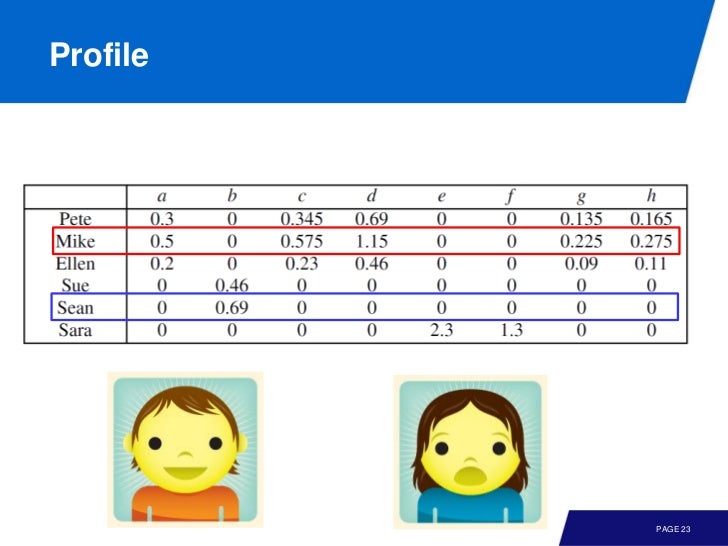
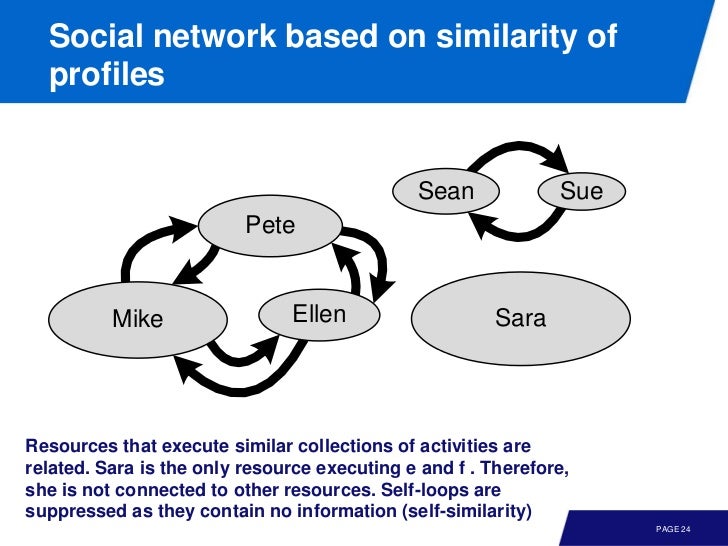
위의 예에서는 resource 기반으로 묶었지만 case 로 묶어 process variants 를 확인할 수도 있다.
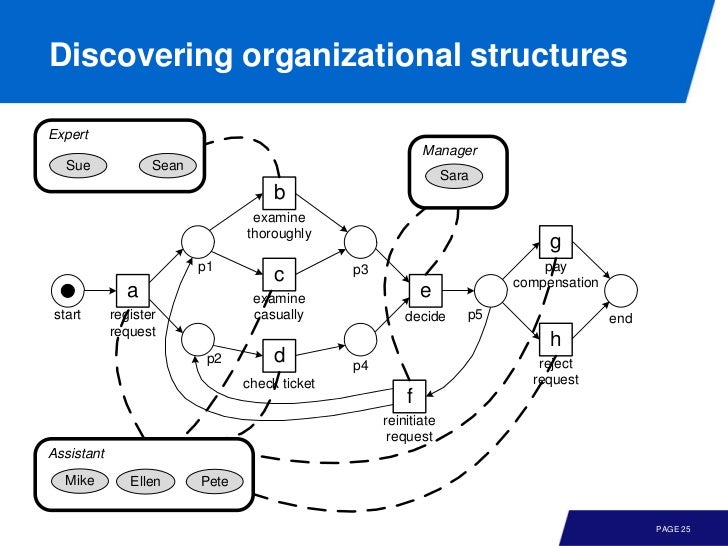
그리고 위에서 발견한 organizational perspective 를 모델에 적용하면 이런 재미난 그림을 얻을 수 있다. 누가 어떤일을 하는지를 넘어, 어떤 집단이 어떤 일을 주로 하는지를 파악할 수 있는 것이다.
프로세스 마이닝을 실제 로그에 적용해 보면 스트레스 대비 일의 퍼포먼스를 설명하는 [Yerkes-Dodson law] 도 볼 수 있다고 한다.

(http://sourcesofinsight.com/)
프로세스 마이닝은 사회과학쪽으로도 유용할 것 같다. 근데 이 그래프는 너무 테일러리즘ㅠ
Conbining Different Perspectives
이 전 까지 배웠던 다양한 perspectives 들
- data perspective
- resource perspective
- time perspective
- control-flow perspective
이런 하나의 모델로 조합해 보자.
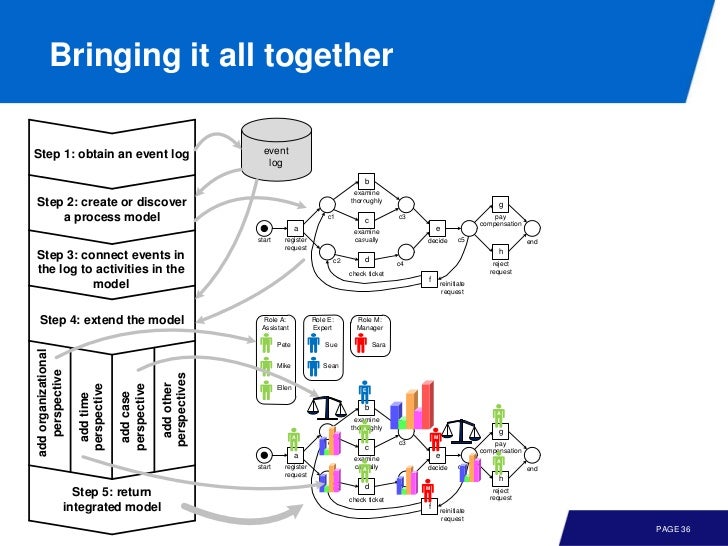
control flow, 즉 모델에
- data perspective 를 추가하면 guard 를 얻을 수 있고
- time perspective 는 wating time, service time 을 확인하는데 도움을 준다
- resource perspetive 는 모델을 role, individual 관점에서 이해하는데 도움을 준다.
이 조합된 모델에 limitation 이 있다는 것, 그리고 이 모든 것은 descriptive(as is) 하다는 것을 명심하자.
다양한 관점이 적용된 모델을 이런 곳에 활용할 수 있다.
- diagnosis
- re-engineering
- 예측이나 추천같은 operational support
- What if 를 다루는 simulation
Comparative Process Mining Using Process Cubes
event log 에는 다양한 attribute 를 가지고 있다. 이것들을 서로 비교해 가면서 더 좋은 프로세스 마이닝 모델을 선택할 수 있다. 즉, 다양한 조합의 액티비티, 케이스, 리소스 등을 선택해 가면서 가장 적합한 모델을 찾아내는 것이다.

이 큐브의 각 축은 차원을 나타내고, 각 셀은 어떤 특정 패턴의 이벤트 로그를 나타낸다 볼 수 있다.
이렇게 프로세스 큐브를 사용하면 다차원 분석이 가능하다. data ware house 나 OLAP 도 비슷한 일을 하긴 하는데, 프로세스 마이닝과의 큰 차이점이 하나 있다.
Related, but often data is aggregated it useless for process mining(events are lost)
Refined Process Mining Framework
전체적인 큰 그림은 아래와 같다.
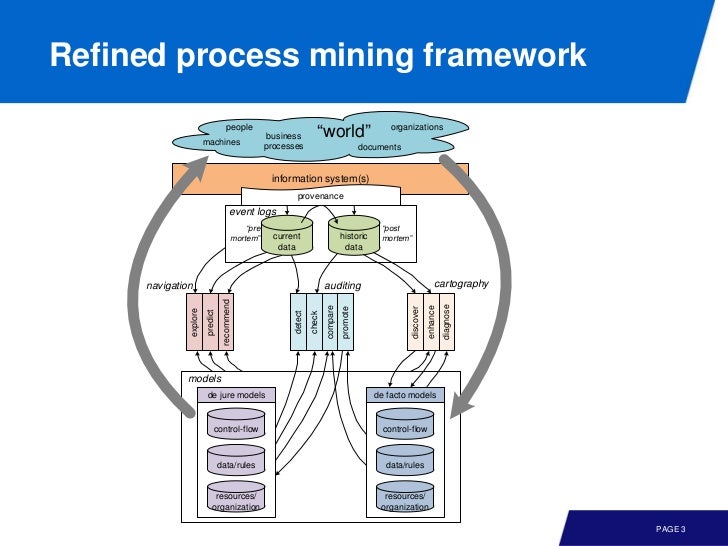
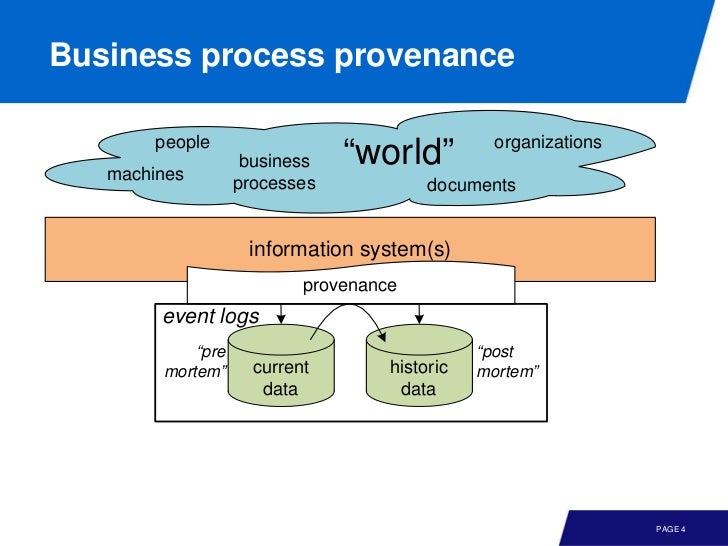
꼭대기부터 차근차근 보자. 여기서 provenance 란 수집하는 이벤트 로그가 신뢰성이 있어야 한다는 것을 의미한다. 그리고 이 이벤트 로그는 두 가지로 나뉘는데
Post mortem event data: refer to information about cases that have completed. i.e., these can be used for process improvement and auditing but not for influencing the cases they refer to
Pre mortem event data: If a case is still running, alive, then it may be possible that information in the event log about this case can be exploited to ensure the correct or efficient handling of this case
즉 pre mortem 은 현재 진행중인 것을 말한다. 와이리 복잡하게 설명하시뮤ㅠ 예를 들어 student-related event data 에서
post mortem: Understanding where and why students drop out or deviate. Should the curriculum be redesigned? What are the bottlenecks?
pre mortem: What advice can we give a particular student that is likely do drop out? How to signal the lecturer that the exam is likely to be a massacre due to inactivity of students?
De Jure vs De Facto
큰 그림에서 밑 부분을 보면 모델에도 두 종류가 있다.
de jure model 은 normative 즉 되어야 하는 것 을 설명하는 것이고, de facto model 은 descriptive, 즉 실제로 행해지는 것 을 설명한다.
Cartography
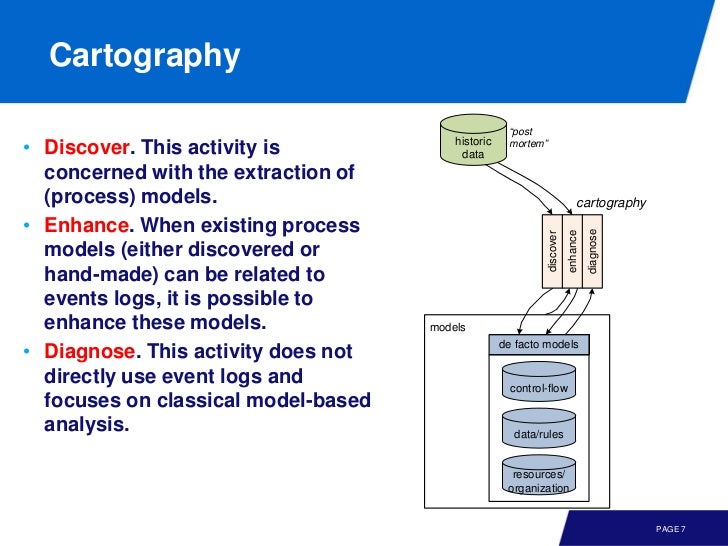
이벤트 로그를 이용해서 모델을 발견하고, 개선하고, 진단하는 과정을 말한다
Auditing
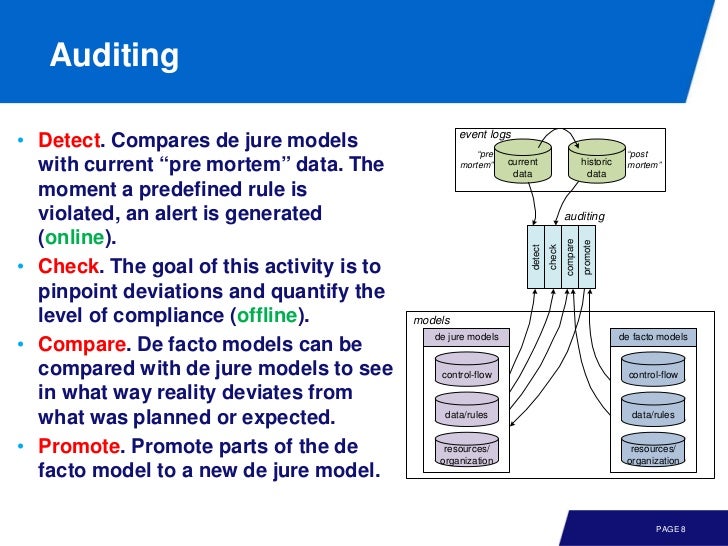
- detect: de jure model 과 pre mortem 을 비교해 violation 이 없는지 확인한다.
- check: detect 에서 찾은 것을 수량화하고, 어떤 deviation 인가 확인한다.
- compare: defacto model 과 비교해서 실제에서 어떤 deviation 이 있는가 본다.
- promote: 위 정보를 토대로 모델을 개선한다.
Navigation
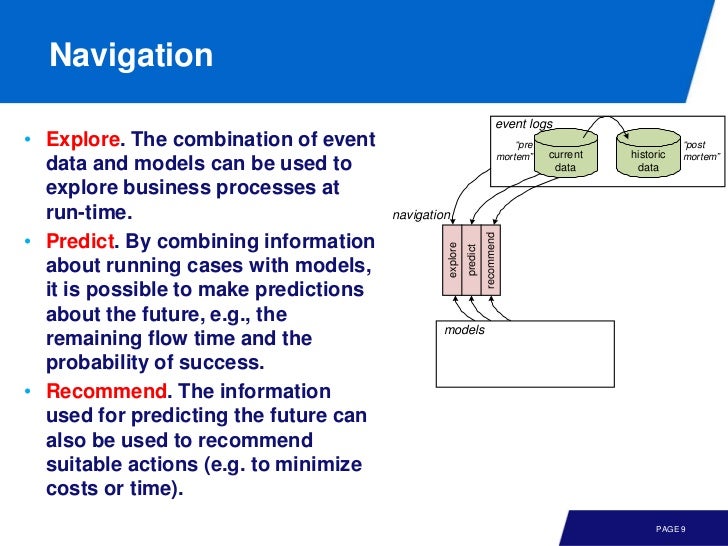
이 단계에서는 런타임에 explore 할 수도 있고, prediction 나 recommendation 도 가능하다.
References
(1) Book: Process Mining
(2) Slide
(3) Process Mining: Data science in Action by Wil van der Aalst
(4) www.processmining.org
(5) http://pais.hse.ru/en/
(6) http://sourcesofinsight.com/
comments powered by Disqus