Process Mining 4: Conformance Checking, Dotted Chart
Two-Phase Process Discovery, Limitations
지난시간에 두 단계를 거치는 프로세스 마이닝 알고리즘을 봤었다.
하나는 heuristic mining 으로 dependency graph 를 만들고, 이것을 C-nets 으로 변환했었다.
다른 하나는 transition system 을 학습하는 것으로 먼저 state abstraction 을 이용해 transition system 을 만들고 여기에 숨어있는 state-based region 을 이용해 Petri-nets 을 만들었다.
그런데, state-based region 접근 방법에는 문제점이 있다.
(1) Inability to discover particular process constructs
(2) Inability to balance the four forces (fitness, precision, generalization, simplicity)
예를 하나 보자. <a, a>^55 란 로그가 있을때 만들어지는 트랜지션 시스템으로 s1 -> s2 -> s3 가 있다. 여기엔 몇개의 non-trivial region 이 있을까?
없다. empty set, {s1, s2, s3} 가 있는데, trivial region 이므로
따라서 이걸 이용해 petri-net 을 만들면 place 가 없는 petri-net 이 만들어 지고, <a, a, a> 등의 로그를 허용하므로 에러가 있다.
<a, c>, <a, b, c>, <a, b, b, c> ... 의 로그를 훈련시켜 만든 트랜지션 시스템은 대략 이런 모양이다
s1 -> s2 > s3 (s2 는 자기 자신으로의 액션 b 가 있음)
이 때 여기에는 non-trivial region 이 3개가 생기는데, 이걸 이용해 petri-net 을 만들면 b 만 붕 떠 있어, b 가 가운데 실행되지 않고 먼저나, 나중에 실행되는 petri-net 이 만들어 진다. underfit 이다.
Petri net can simulate the behavior of the transition system, but not the other way around (no bisimulation)
첫 번째 문제같은 경우는 forward closure 속성을 검사해서, 문제가 발견되면 label 을 spliting 하는걸로 해결할 수 있다. (이미지를 첨부하고 싶은데 찾을 수가 없다.) 두 번째 문제도 같은 방법으로 해결할 수 있다. ProM 에는 bisimulation 을 위한 플러그인이 있다.
이제 특정 프로세스 패턴을 발견하지 못하는 문제를 해결했다. 이제 문제 (2) 를 해결해 보자.
(2) Inability to balance the four forces (fitness, precision, generalization, simplicity)
먼저 step 1 에서 트랜지션 시스템을 학습할때는 fitness, generalization, precision, simplicity 의 trade-off 를 봐가면서 해야한다.
step 2 에서는 region 을 이용해서 concurrency 를 발견하는데 사실 잘 생각해 보면 Petri-nets 은 트랜지션시스템에서의 변환이므로 이 단계에서는 simplicity 나 generalization 의 개선 여지가 없다. 트랜지션 시스템이 이미 복잡한데 어떻게 페트리넷을 간단하게 할까? 마찬가지로 트랜지션 시스템이 이미 overfit 되어있는데, 어떻게 이 문제를 풀까? 이 두 가지 문제를 해결하려면 (1) 로 돌아가야 한다.
정리하자면 Region-based techniques 은
- Overfitting may be a problem
- Inability to leave out infrequent behavior (but can be done in the transtion system)
- Noise and incompleteness connot be handled well
Alternative Process Discovery Techniques
이전까지는 모델의 퍼포먼스를 기준으로 삼았지만 사실
- speed
- memory usage
- representational bias
- flexibility(related problems),
- implementation vs apporach
등을 고려해야 한다.
petri net 에서 무엇을 해야 behavior 를 추가할 수 있을까? place 는 일종의 constraint 라 보면 된다. 그리고 place 에 토큰이 많아지면 다 더 다양한 로그가 생길 수 있다.
- Add a transition
- Remove a place
- Add an arc from a transition to a place
- Remove an arc from a place to a transtion
반대로 behavior 를 제거하려면
- Remove a transition
- Add a place
- Add an arc from a place to transition
- Remove an arc from a transition to a place
process discovery 가 finding place 라는 점을 고려하면 alpha algorithm 에서는 constraint 인 place 를 발견하는 과정이었다. state-based region 에서는 먼저 transition 을 만들고, 이걸 place 로 변환했었다.
이번엔 language-based region 이란 기법을 배워보자.
Language-based Region
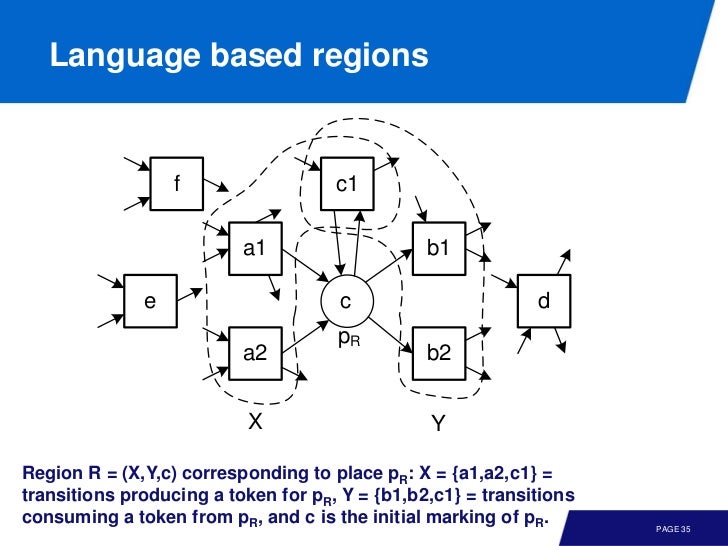
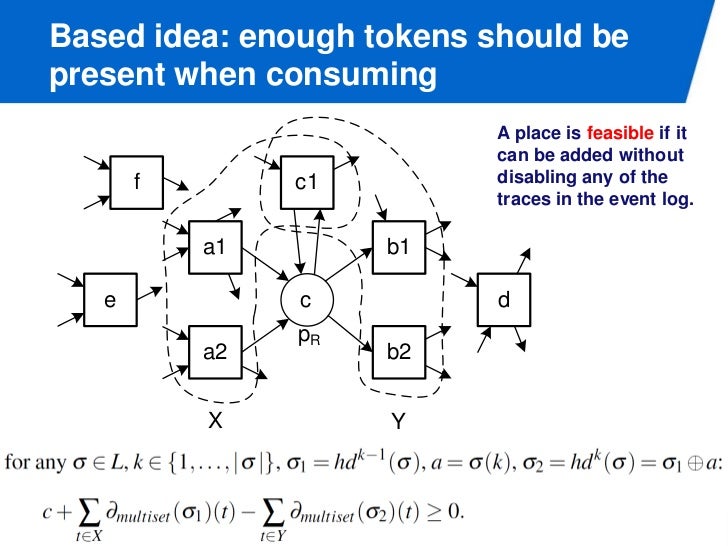

c * 1 + A' * x - A * y >= 0 등의 식으로 표현되는데, 이 말은 place 가 음수가 될 수 없다는 뜻이라 보면 된다. 이제 나도 뭔소린지 모르겠다 너무멀리 와버렸음 ㅠㅠ
여기서 A', A 는 log, x, y 는 petri-nets, c 는 초기에 place 내에 있는 토큰의 수다. 이 때 위 방정식을 만족하는 x, y, c 가 region 이다.
cis the initial number of tokens in the place
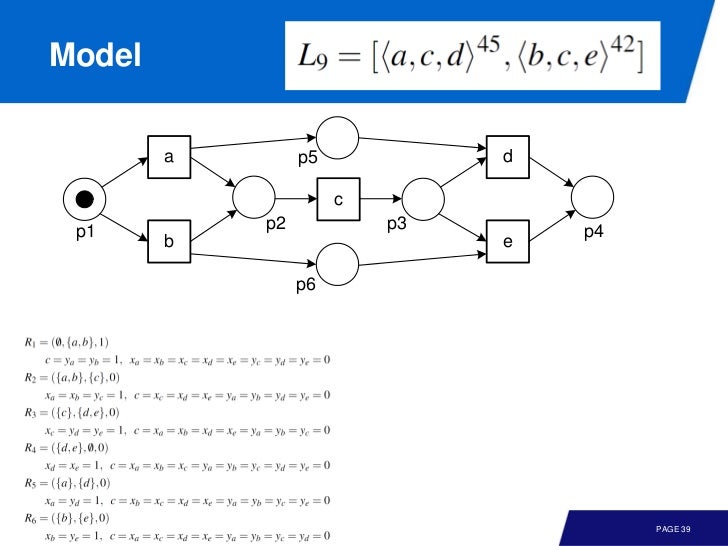
예를 들어
<a>, <b>, <a, b>, <b, a> 인 로그가 있다고 하자. 그러면 진리표처럼 로그 내에 a, b 쌍을 0, 1 로 표현할 수 있다. 이걸 A 라 하면
그리고 A' 를 만들기 위해 마지막 trace 는 무시하도록 하자. 그러면 다음 식을 만들 수 있다.
x_ais the number of arcs from transitionato the placex_bis the number of arcs from transitionbto the placey_ais the number of arcs from the place to transtionay_bis the number of arcs from the place to transtionb
식을 풀면
하나의 답으로
c=1, x_a=0, x_b=0, y_a=1, y_b=0c=1, x_a=0, x_b=0, y_a=0, y_b=1
language-based region 에서는
- any solution is a feasible place
- additional constraints can be added easily
- goal function can be used to select most interesting places
- optimiazation problem (e.g ILP)
Genetic Process Mining
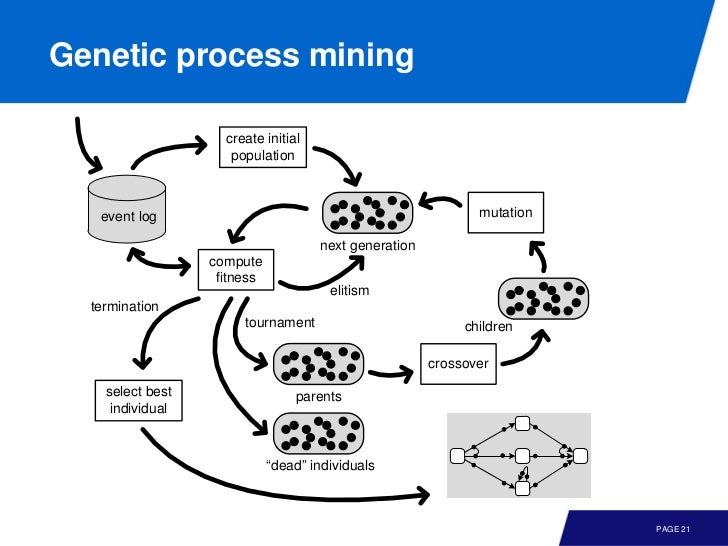
이번엔 genetic process mining 기법을 살펴보자.
event log 로 부터 initial population 을 만들고, 이것에 대해 conformance checking 등을 이용해 얼마나 좋은 모델인가 본다. 이것을 다시 매 턴마다 랜덤하게 변이시키면서 계속 반복하는 것이다.
많은 generation, mutation 이 있을 수 있기 때문에 굉장히 느리지만 very flexible 할 수 있다. 왜냐하면 qualty measure 을 이용해서 4 품질(fitness 등) 을 조절할 수 있기 때문이다.
Inductive Process Mining
로그를 trace 를 기준으로 쪼개는 방법인데
abdef
acdef
abdeg
adceg
가 있을때, abcd, efg 기준으로 쪼개면
abd
acd
abd
adc
ef
ef
eg
eg
로 분리할 수 있다. 여기서 abcd 부분을 또 쪼개면 a seq bcd 로 쪼갤 수 있다. 마찬가지로 뒷부분도 e seq fg 로 쪼갤 수 있다. 뒷부분의 경우 f xor g 로 다시 쪼갤 수 있고. 이렇게 반복하면서 쪼개는 방법이다. 이 결과로 만들어지는 것이 process tree 다. 이를 petri-net 이나 BPMN 으로 변경할 수 있다.
ProM 에도 플러그인이 있다고 함.
Intro to Conformance Checking

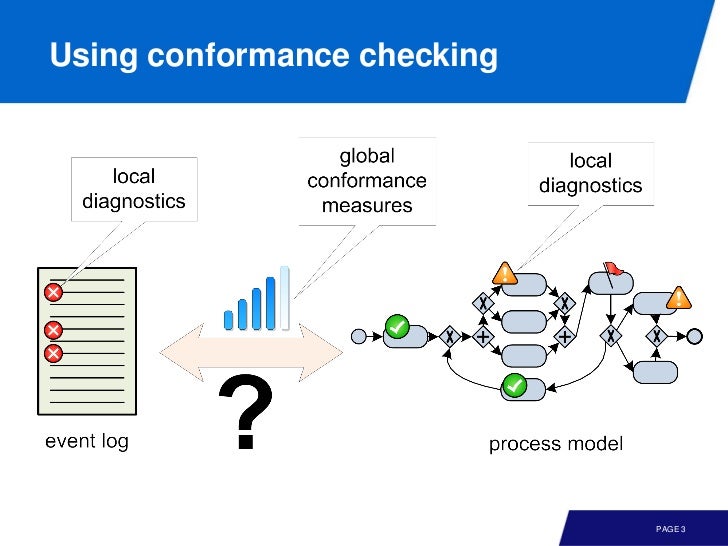
다른 품질도 중요하긴 한데, replay fitness 가 주된 관심사라고 한다. conformance checking 의 주된 용도는
- Auditing and compliance
- Evaluating process discovery algorithm
- Conformance to specification (software, service)
conformance checking 은 runtime 에 할수도 있다.
Footprints-based Conformance Checking
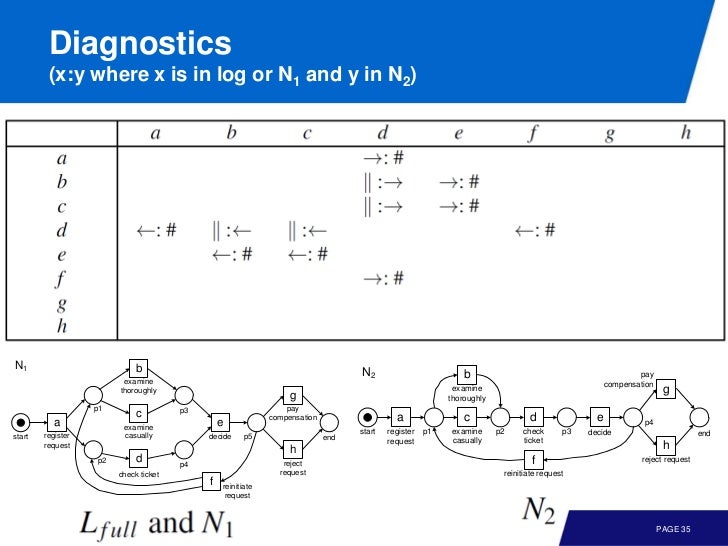
알파 알고리즘을 사용할때 footprints 를 봤었다. 테이블에 각 trace 사이의 direct succession, causality, parallel, choice 를 표시한 것이다.
로그로 부터 footprint 가 나왔기 때문에 로그의 footprint-based conformance 는 항상 1 이다. 다시 말해서
footprints of log and model coincide
그런데, 모델을 만들고 보니 다음과 같이 로그와 모델의 footprint 를 작성했다고 하자.

a - d, b - d 부분이 다르다. 따라서 다른 부분을 파악해서 값으로 매기면

flower model 에서는 수 많은 조합이 가능하기 때문에 footprint-based conformance 가 떨어진다.
footprint-based conformance 자체는 굉장히 유연하다.
- log to log
- log to model
- model to model
모두 가능하다. 그러나
- frequencies are not used
- behavior is only considered indiretcly (directly follows relation)
- aims to capture fitness, precision and generalization in a single metric
다양한 metric 으로 fitness 을 분류하고 싶을 수도 있는데, footprint-based 는 그러질 못한다. 이 때문에 token-based conformance 를 이용하기도 한다.
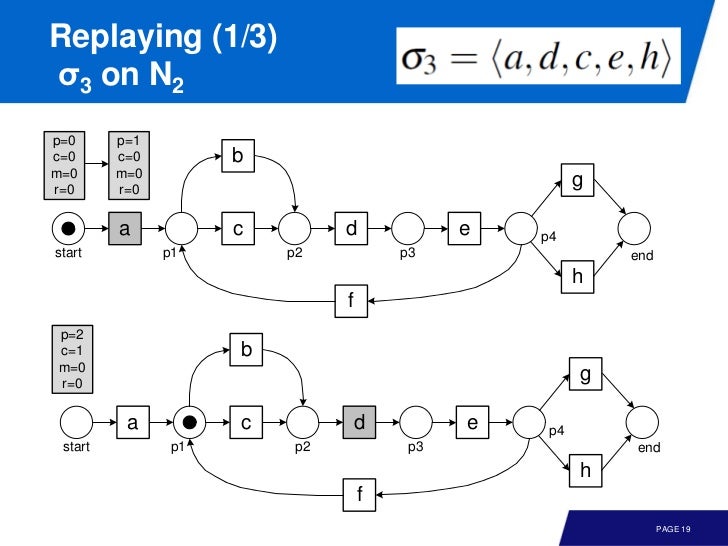
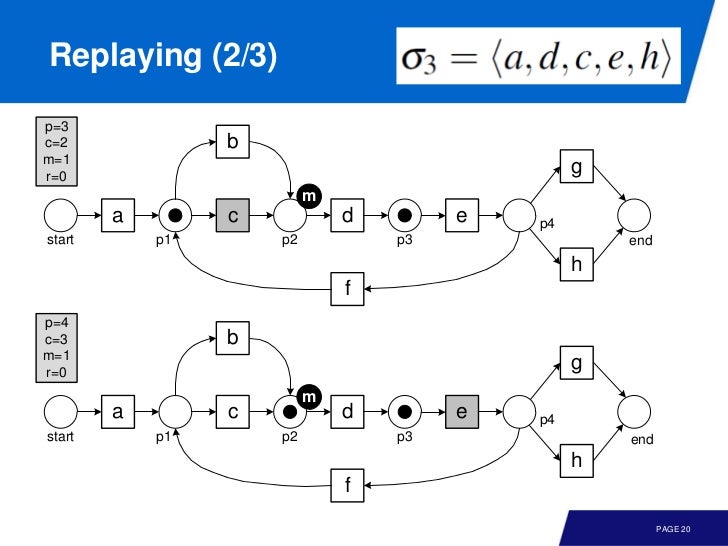
Token-based Replay
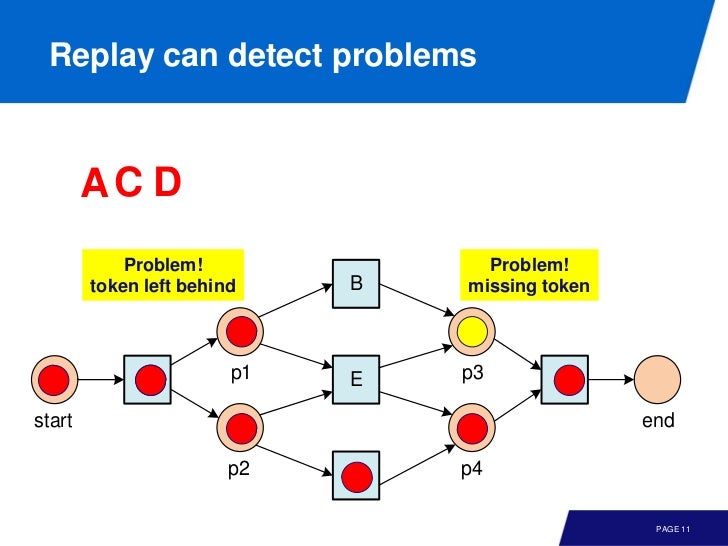
traces 를 모델에 실제 replay 해 보면서 missing token, remaining token 을 기록한다.
p, produced tokensc, consumed tokensm, missing tokensr, remaining tokens
그리고, 어느 place 에서든 invariants 는
replay 의 시작과 끝을 생각해 보면
- In the beginning, a token is produced for the source place
p = 1 - At the end, a token is consumed from the sink place (also if not there)
c' = c + 1
뭔 소린가 했는데, conformance checking 을 위해 초기에 토큰을 하나 넣어주고, replay 가 끝났을 때 sink place 에서 consume 해서 c 값을 하나 증가시킨다는 이야기
왼쪽 위의 값을 주목하면서 따라가 보자.
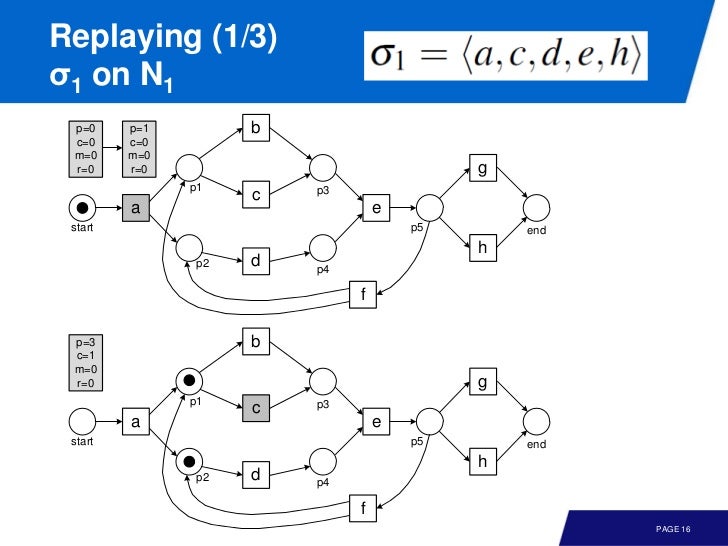
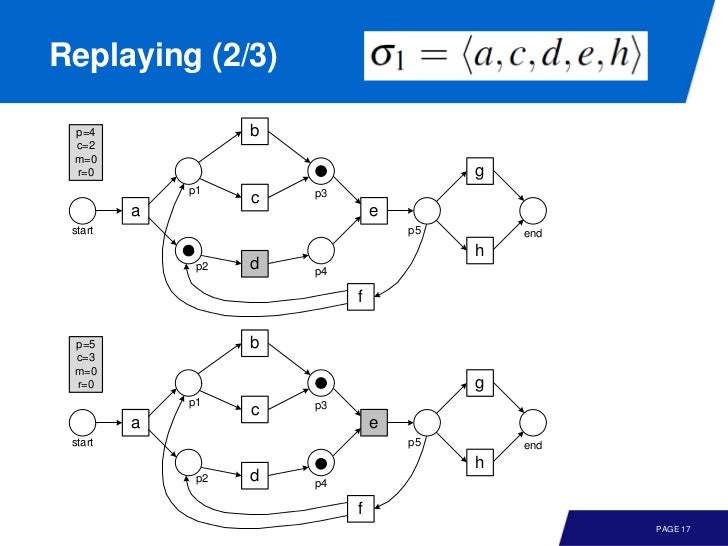
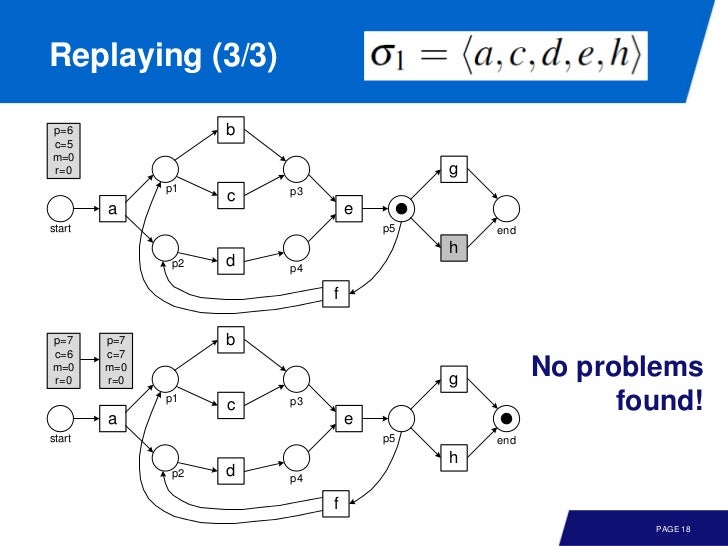
이번엔 좀 문제가 있는 event log
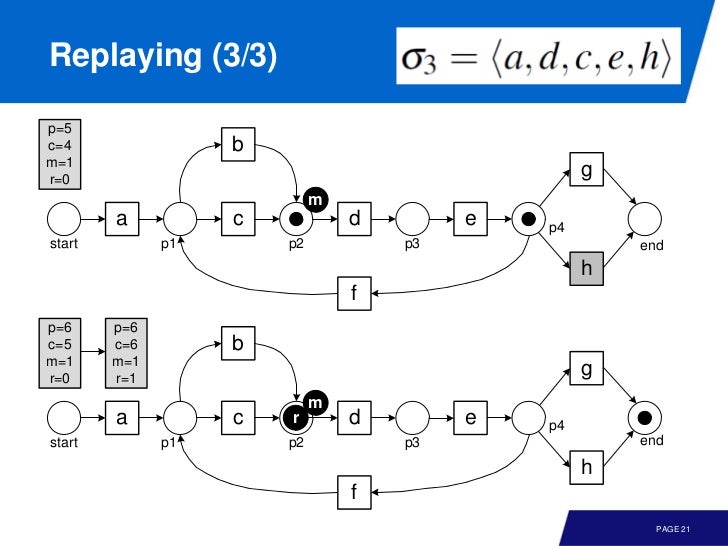
각 log 가 transition 에서 얼마나 실행되었는지 기록해서 모델에 어떤 문제가 있는지 파악할 수 있다.
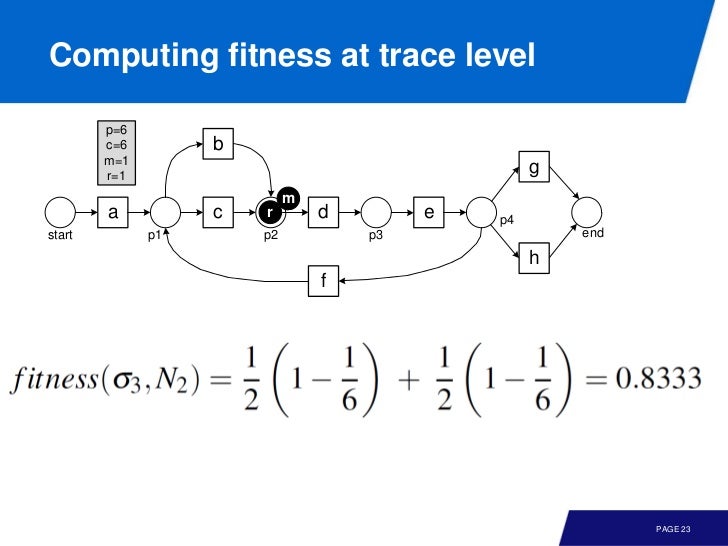
frequency 는 p, c, m, r 에 곱해서 전체 fitness 값을 얻으면 된다.
만약 consumed token 이 모두 missing token 이고, produced token 이 모두 remaining token (미사용) 이면 fitness 는 0 이다.
Limitations
- Basic replay approache assumes visible, unique labeled transitions
- ProM implementation uses heuristics to deal with slient transitions having same label
- Conformance value is too optimistic due tu token flooding
- Local decision marking may misleading
특히 마지막은 중요한데, 우리는 value 를 보고 싶은게 아니라 closest path 를 보고싶어 할수도 있다.
예를 들어 <a, c1, c2, c3, e1, e2, e3> 값이 0.8 로 나왔다 하면, “그럼 올바른 path 는 무얼까?” 하고 질문할 수 있다.
Replay technique does not provide corresponding path through model
다음장에서 배울 alignment 를 이용하면 모델에서 가능한 real path 를 얻을 수 있다.
Alignment-based Conformance Checking
먼저 생각해 볼 거리는
Conformance checking should not impose restriction on the process notation e.g slient transitions and two transitions with same label should be possible
Should provide closest maching path (required for performance analysis)
특히 closest maching path 가 제공되면 fitness 를 넘어 generalization, precision, bottle-neck 등에 이용할 수 있다. 대략 이런 느낌이라고 보면 된다.
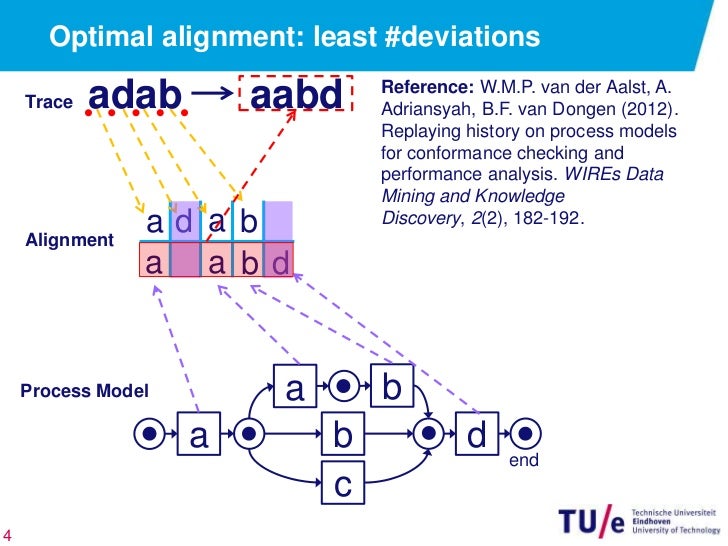
즉 replay 불가능한 로그에서 replay 가능한 로그와 차이점을 반영한 것이라 보면 된다. 그러면, 다음중 어떤 것이 더 possible 한 로그일까?
a >> c1 c2 e1 e2 e3 // invalid path
>> b c1 c2 e1 e2 e3 // valid path
a1 c1 c2 >> >> >> e1 e2 e3 // invalid
a1 c1 c2 d1 d2 d3 >> >> >> // valid
이건 cost function 에 따라 다르다. standard cost function 의 경우 >> (move) 의 수를 센다.
근데 몇 가지 생각해볼 거리가 있다. -2 와 +2 의 cost 가 있을 때 어떤 것을 택할건가 하는 문제들이다. 이 차이 때문에 루프가 있을수도 있다.
Alignment-based Fitness
1 에서 optimal cost / worst cost 를 빼면 된다. 강의에서 나오는 log 의 경우
// optimal
a >> c1 c2 e1 e2 e3
>> b c1 c2 e1 e2 e3
// worst
a1 c1 c2 e1 e2 e3 >> >> >> >> >> >>
>> >> >> >> >> >> b1 c1 c2 d1 d2 d3
따라서 1 - (2 / 12) = 0.83
alignment-based conformance checking 의 장점으로는
- observed behavior is directly related to modeled behavior
- very flexible (any cost structure)
- detailed diagnostics
- after aligning log and model, other quality dimensions can be investigated
다른 장점으로는 drilling down 도 있다. 즉 replay 되는 것과 아닌 것을 분리해서 분석할 수 있다는 뜻이다. 분리 된 것중 이상한 로그를 새로운 로그처럼 취급해서 다양한 기법들을 적용할 수 있다.
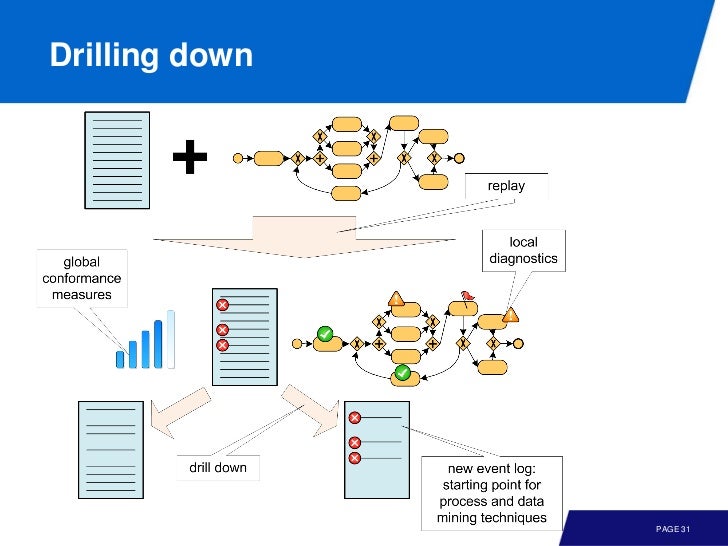
지금까지 fitness 만 좀 봤지만 다른 퀄리티에 대해서도 적용 가능하다. 그리고 지금까지는 control flow 관점으로 좀 봤는데, cost, time 등 다른 기준으로도 볼 수 있다. 이를 위한 기법으로 data-aware alignments 가 있다.
Exploring Event Data

멘탈이 터짐
model view, instance view, event view 사이에 관계가 있다고 함.
Dotted Chart
모든 이벤트를 볼 수 있는 일종의 view 인데 dot 과 event 사이에는 1:1 관계가 있다. 모든 event 에는 timestamp 가 있는데, 이것을 이용해 X 를 계산하고 다른 attribute 를 이용해서 Y 축을 잡는다. 액티비티나 리소스에 따라 다른 색을 가질 수 있다.
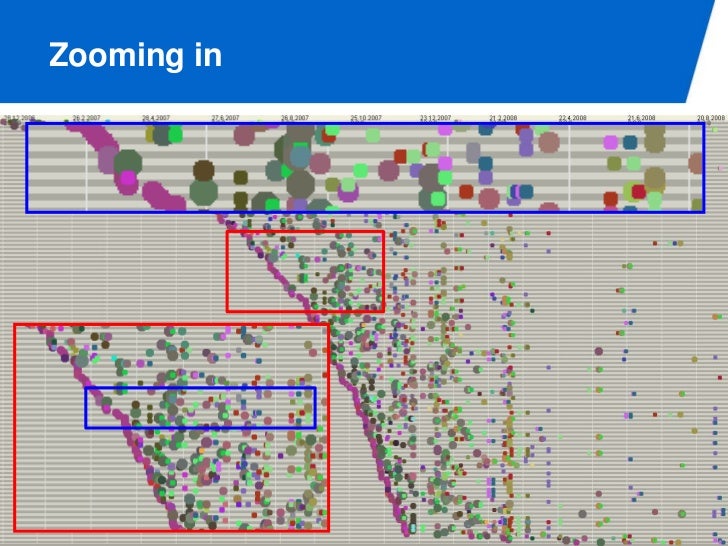
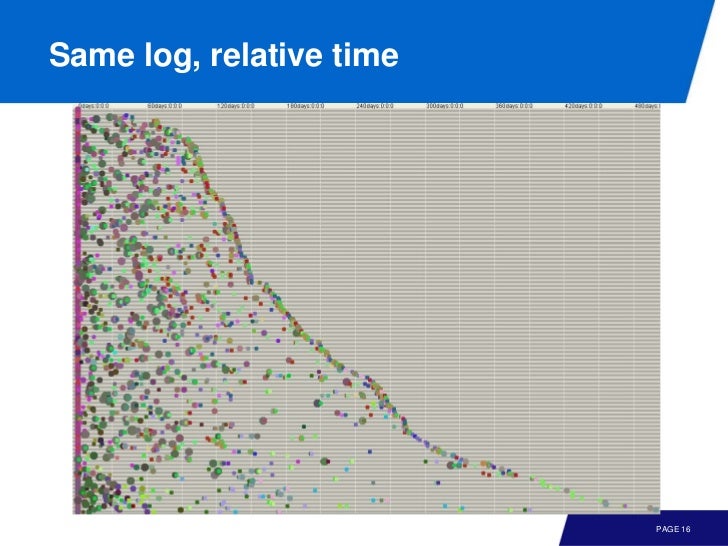
이게 중요한 이유가 Y 축과 컬러를 어떻게 하느냐에 따라 정말 다양한 view 를 얻을 수 있다. 그래서 강의에서 헬리콥터 뷰 라고 표현함. 심지어 time 을 logical time (step 1) 등으로 수정해서 볼 수도 있다.
다양한 뷰를 조절해 가면서 왜 delayed 되었는지, decision 이 없다면 이전 스텝이 무엇인지 등을 파악할 수 있다.
dotted chart 를 이용하면 모델을 작업 하기 전에 input 만을 이용해 다양한 직관을 얻을 수 있다.
References
(1) Book: Process Mining
(2) Slide
(3) Process Mining: Data science in Action by Wil van der Aalst
(4) www.processmining.org
(5) http://fluxicon.com
(6) http://www.win.tue.nl
(7) Temporal Compliance Checking
(9) Alignment-based onformance Checking
comments powered by Disqus