Pattern Discovery 3: Sequential Pattern Mining

이번 시간에 배울 주제는 Sequential Pattern Mining 입니다.
- GSP (Generalized Sequential Patterns)
- Vertical Format-Based Mining: SPADE
- Pattern-Growth Methods: PrefixSpan
- Mining Closed Sequential Patterns: CloSpan Constrain-Based Sequential Pattern Mining
sequential pattern mining 은 다양한 곳에 사용됩니다.
- customer shopping sequences
- medial treatments
- web click streams, calling patterns
- program execution sequences (software engineering)
- biological sequences (DNA)
time-series DB 와는 다릅니다. 이건 일정 간격으로 로그가 저장된 것이고, sequential pattern 은 time stamp 가 붙은 것이라 보면 됩니다. 어찌 보면 [Process Mining][http://1ambda.github.io/process-mining-week1/] 이라 볼 수도 있겠습니다.
sequential pattern 은 크게 gapped 와 non-gapped 로 나누어집니다. 전자는 패턴 사이의 gap 을 허용하고, 후자는 허용하지 않습니다. 모든 시퀀스가 중요하다는 뜻입니다. 예를 들어 웹사이트에서 click stream 사이의 gap 은 정말 중요할 수 있습니다.

sequential pattern mining 은 주어진 시퀀스에서 빈번한 서브시퀀스의 집합을 찾아냅니다. element (()) 또는 event 라 부르는 단위가 items 를 담고 있습니다. 그리고 () 로 묶인 item 의 순서는 중요하지 않습니다.
GSP
GSP 는 apriori-based sequential pattern mining 기법입니다.
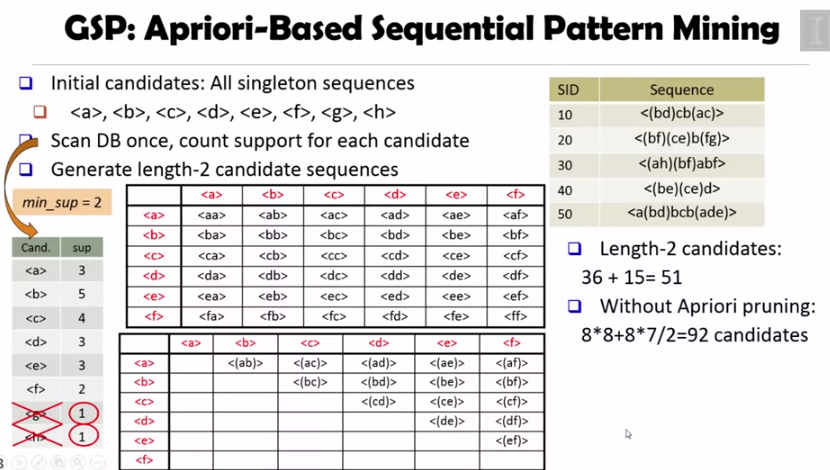
singleton 시퀀스를 기반으로 length 1, 2 의 candidates 를 만들고, apriori pruning 을 적용합니다. 그러면, 36 + 15 = 51 의 candidates 를 얻을 수 있습니다.
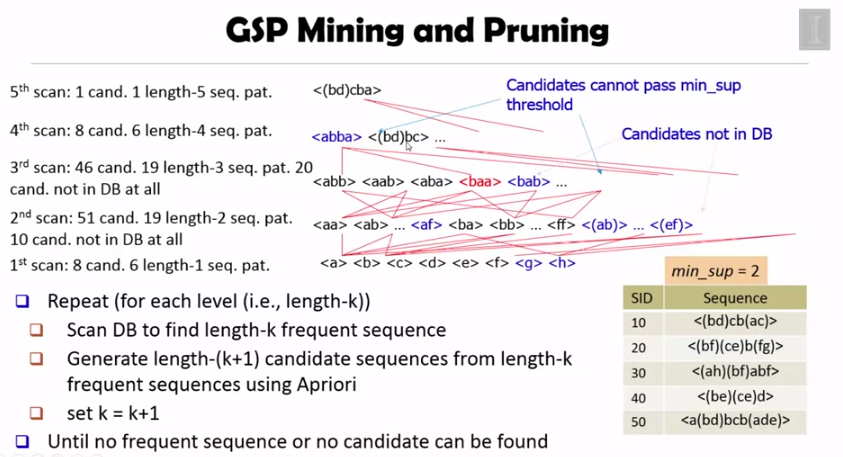
데이터베이스를 지속적으로 스캔해가면서 minimum support 를 통과하지 못하는 것들을 제거하고 위 과정을 반복하는 것이 GSP Mining 입니다.
SPADE
SPADE (Sequential Pattern Mining in Vertical Data)
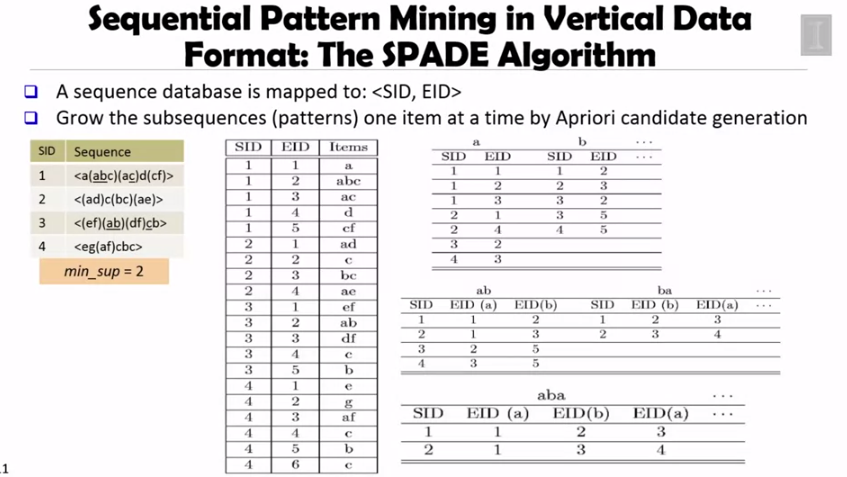
SID 뿐만 아니라 element ID, EID 를 이용해서 테이블을 좌측처럼 하나 만듭니다. 그리고 이 테이블을 이용해서 우측 상단 테이블처럼 a, b 등이 어느 SID, EID 셋에서 나타나는지를 파악합니다. 패턴의 길이를 늘려가면서, 즉 테이블을 계속 조인해 나가면 패턴의 support 를 구할 수 있습니다.
PrefixSpan
Pattern-Growth 기반의 알고리즘인 PrefixSpan 을 살펴보겠습니다.

먼저 length-1 패턴을 찾고 이를 기반으로 projected DB 를 만들어가며 마이닝을 진행합니다.
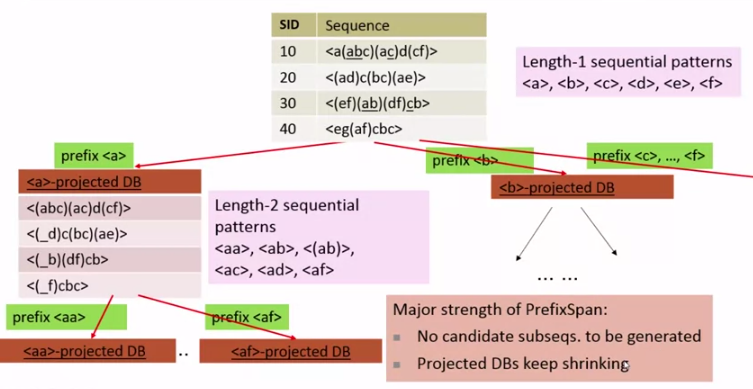
단계가 지나면 지날수록 candidate 가 생겨나는 비율이 줄고, projected DB 자체도 줄어든다는 장점이 있습니다.
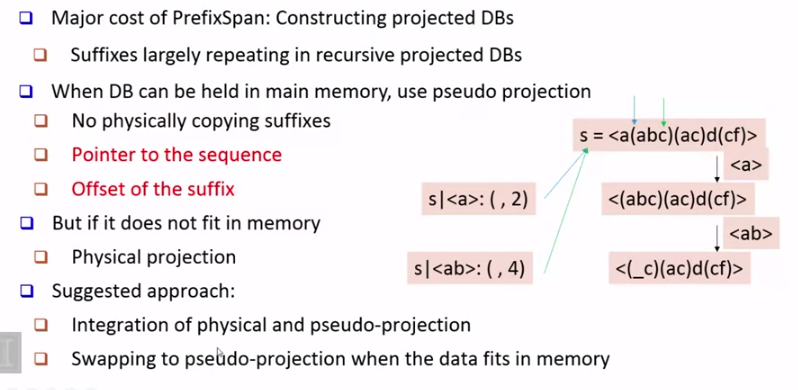
다만 projected DB 에서 많은 중복이 발생하기 때문에 이를 해결하기 위해 pseudo projection 을 이용할 수 있습니다.
CloSpan
CloSpan 은 closed sequential pattern 을 마이닝하는 알고리즘입니다.
closed pattern 을 다시 복습해 보면
closed pattern: A pattern(itemset)
Xis closed ifXis frequent, and there exists no super patternY⊃X, with the same support asX
예를 들어 <abc>:20, <abcd>:20, <abcde>:15 라면 <abcd> <abcde> 는 closed pattern 입니다.
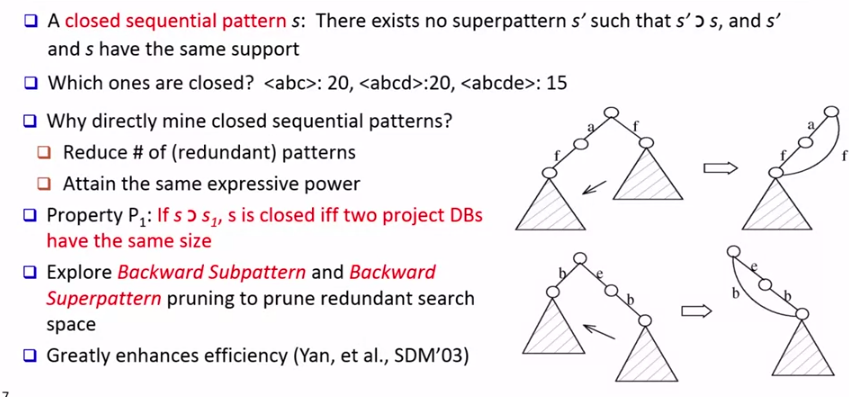
closed pattern 을 마이닝하는 이유는 이전에도 말했듯이 중복된 패턴을 피하기 위함입니다. 위 그림처럼 redundant search space 를 pruning 할 수 있습니다.
Constraint-Based

- Data anti monotonic:
S가 제약조건c를 위반했을때, 나머지 부분인s를 더해도 여전히 위반이라면s를 제거할 수 있습니다. - Sunccint: 제약조건
c를 기준으로 데이터를 직접 조작합니다. 예를 들어S가{i-phone, MacAir}를 반드시 포함해야 한다고 할때, 그렇지 못하면S를 제거할 수 있습니다 - Convertible: 아이템을 정렬해서 제약조건을 anti-monotonic 이나 monotonic 등으로 바꿉니다.

- order constaint 는 anti-monotonic 입니다
- min, max gap 제약조건은 succinct 입니다.
- max span 제약조건은 처음과 마지막 element 의 시간 간격입니다. 이것도 succinct 입니다
- window size 제약조건은 한 element 내부에서 event 발생 회수를 제한하는 조건입니다.

정규표현식과 episode 는 sequential pattern 의 다른 표현 방법입니다.
Graph Pattern Mining
이번 시간에 배울 내용은 다음과 같습니다.
- Apriori-Based Graph Pattern Mining
- gSpan: A Pattern-Growth-Based Method
- CloseGraph: Mining Closed Graph Pattern
- Graph Indexing
- Top-K Large Structural Patterns in a Massive Network
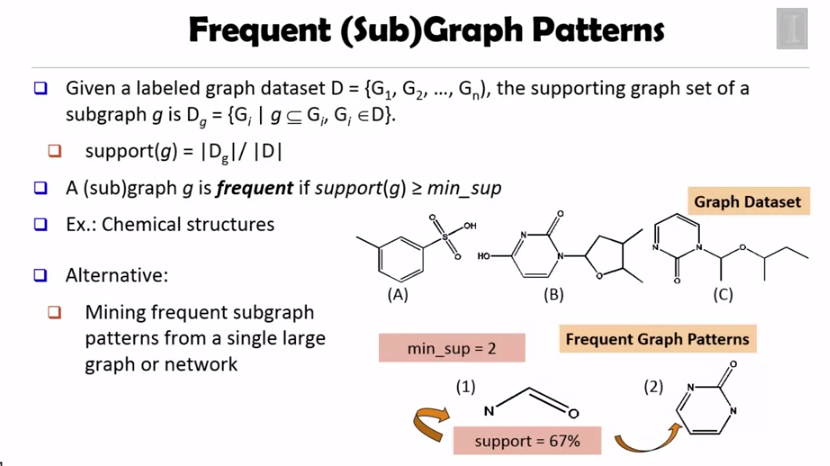
Graph 에서 support 란 subgraph 가 나타나는 수 입니다.
그래프 패턴 마이닝을 위해서 다양한 방법을 이용할 수 있습니다.
(1) Generation of candidate subgraphs
- Apriori (FSG) vs Pattern Growth(gSpan)
(2) Search Order
- Breadth vs Depth
(3) Elimination of duplicate subgraphs
- Passive vs Active (e.g gSpan)
(4) Support calculation
- Store embeddings (e.g GASTON, FFSM, MoFA)
(5) Order of Pattern Discovery
- Path -> Tree -> Graph (GASTON)
Apriori-Based Approach

Apriori Property 에 의해서, 어떤 그래프가 G 가 빈번한 경우는, **모든 **서브그래프들도 빈번할 경우뿐입니다.
따라서 k 개의 edge, vertex 를 가진 frequent 서브그래프에서 공통된 엣지가 많은 그래프를 골라 k+1 개의 edge, vertex 그래프를 만듭니다. 그리고 여기서 이 그래프의 모든 서브 그래프가 frequent 한지 검사하여 pruning 을 진행할 수 있습니다.
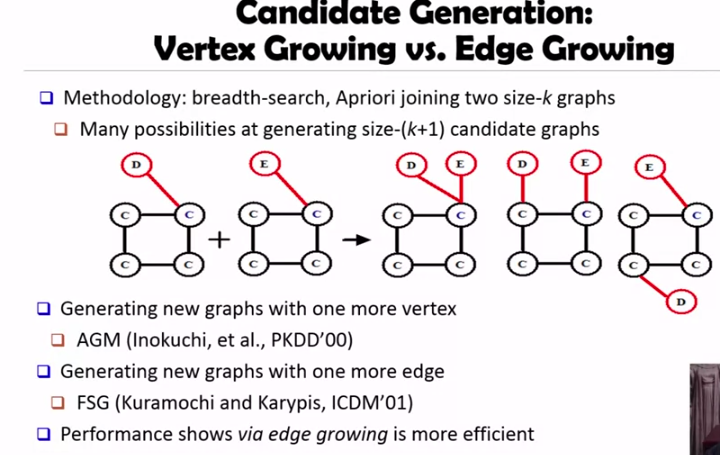
vertex 기반으로 확장해 나가는 알고리즘으로 AGM (Apriori-based Graph Mining) 이 있습니다. edge 를 확장해 나가는 알고리즘으로는 FSG (Frequent Sub Graphs) 가 있는데, 일반적으로 더 작은 컴포넌트인 edge 를 확장시켜 나가는 방법이 더 효율적이라고 알려져 있습니다.
gSpan: A Pattern Growth Approach

먼저 k-edge 그래프를 보고, 여기에 하나의 edge 를 더해 k+1 edge 그래프도 빈번하다면 이 과정을 계속 반복해 나아갑니다. 이 방법은 많은 수의 subgraph 가 중복된다는 단점이 있습니다.
이 문제를 해결하기 위해 gSpan 에서는 생성할 subgraph 의 순서를 미리 정의해 놓고 depth-first search 를 이용해서 graph 를 sequence 처럼 펼칩니다.

위 그림에서는 가장 작은 인덱스를 먼저 선택하는 DFS 를 이용해서 우측처럼 시퀀스를 만들었습니다.
CloseGraph
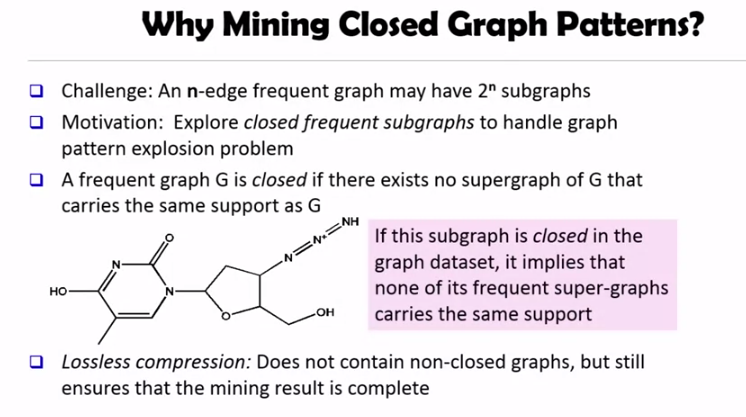
n 개의 edge 를 가진 그래프에는 2^n 개의 서브그래프가 존재합니다. 정말 어마어마한 숫자입니다. 이런 explosion 문제를 해결하기 위해 closed frequent subgraph 를 이용합니다.
- A frequent graph
Gis closed if there exists no supergraph ofGthat carries the same support asG‘
loseless compression 이기 때문에 결과는 complete 합니다. 따라서 closed graph pattern 을 마이닝 하면 좀 더 효율적입니다.
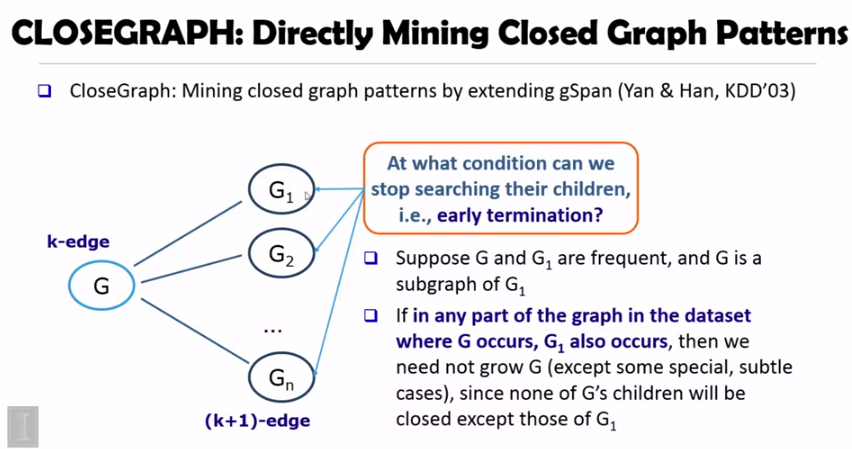
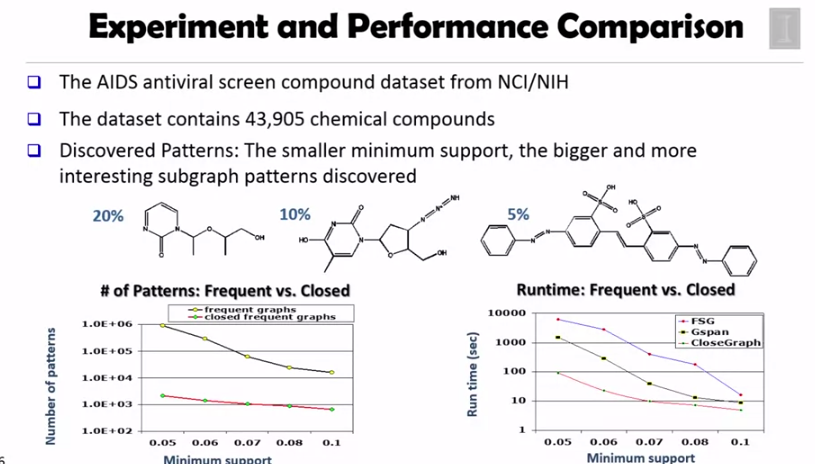
G 가 있을 때마다 G1 이 존재한다면 다른 supergraph 를 살펴볼 필요가 없습니다. 이는 G1 이 G 를 커버할 수 있기 때문입니다. 아래는 다른 알고리즘과의 성능 비교입니다.
Graph Index
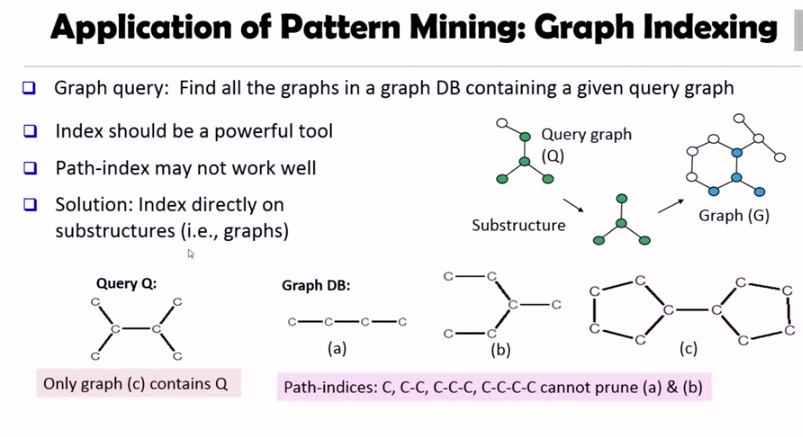
그림에서 볼 수 있듯이 path index 는 (a) (b) 를 쿼리 Q 에 대해 필터링 하지 못할 수 있습니다. 따라서 그래프를 직접 인덱싱하는 것이 필요한데, 문제는 그래프를 인덱싱할때 서브그래프가 너무 많다는 것입니다.

따라서 frequent substructure 만 인덱스 하되, size-increasing support threshold 를 이용하면 됩니다. 즉 사이즈가 증가할수록 min support 도 올리는 것인데, 이는 큰 그래프일수록 작은 그래프에서 이미 indexed 되었을 수 있기 때문입니다.
그리고 discriminative substructure 를 인덱싱해야합니다. 이는 기존과 비슷한 그래프를 인덱싱 할 필요는 없기 때문이지요. discriminative 그래프를 선택하기 위해서 슬라이드처럼 새로운 그래프 x 가 기존의 인덱싱된 그래프 f1, f2, ..., 을 얼마나 커버하는지를 계산하여 작으면 인덱싱합니다.
Spider Mine

pattern fusion 과 비슷하게, 작은 컴포넌트인 spider 가 모여 결국에는 큰 컴포넌트를 만든다는 기본적인 아이디어로부터 시작합니다.
r-Spider 는 vertex u 로부터 r 홉 안에 도달할 수 있는 frequent 패턴입니다.

알고리즘이 수행되는 동안 spider mine 알고리즘은 large pattern 을 유지하고 small pattern 을 pruning 합니다. 그 이유는 작은 패턴일수록 random draw 에서 hit 할 확률이 낮고, 했다 하더라도 여러번 hit 할 확률은 더 낮기 때문입니다.
Pattern-Based Classification
이번 챕터에서 배울 내용은 다음과 같습니다.
- Pattern-Based Classification
- Associative Classification
- Discriminative Pattern-Based Classification
- Direct Mining of Discriminative Patterns
frequent pattern mining 과 classification 을 조합하면 더 심도있고, 다양한 데이터에 대한 분석이 가능합니다.
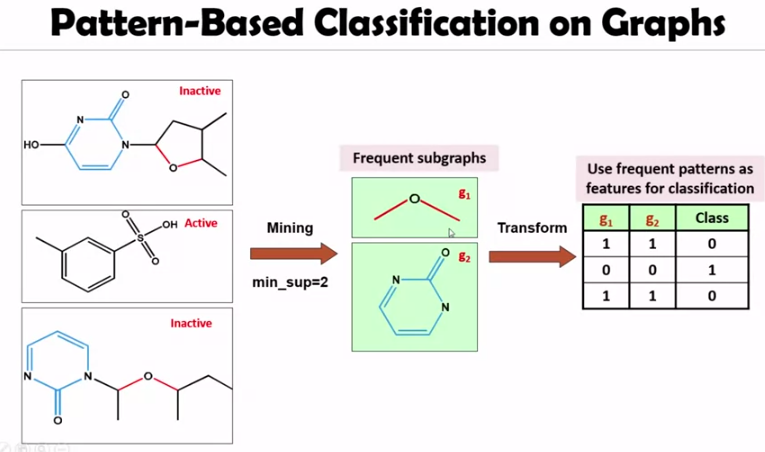
Associative Classification: CBA, CMAR


Discriminative Classification

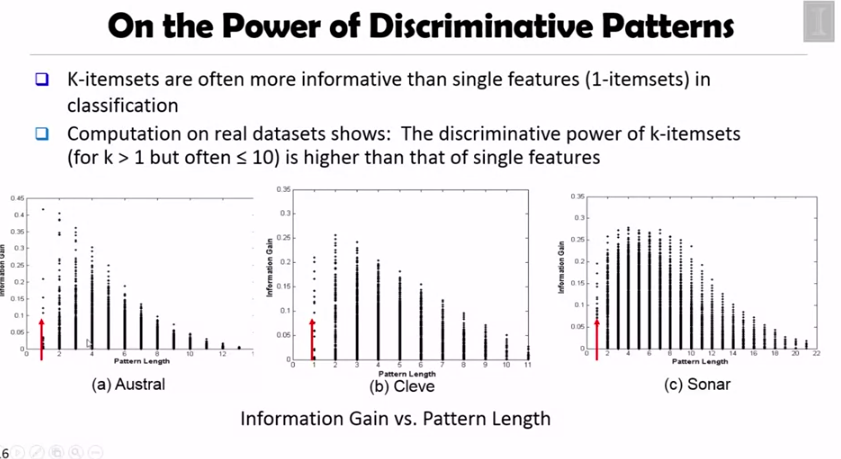
당연한 이야기지만 single item 보다는 k 개의 아이템셋이 더 많은 information gain 을 만듭니다.
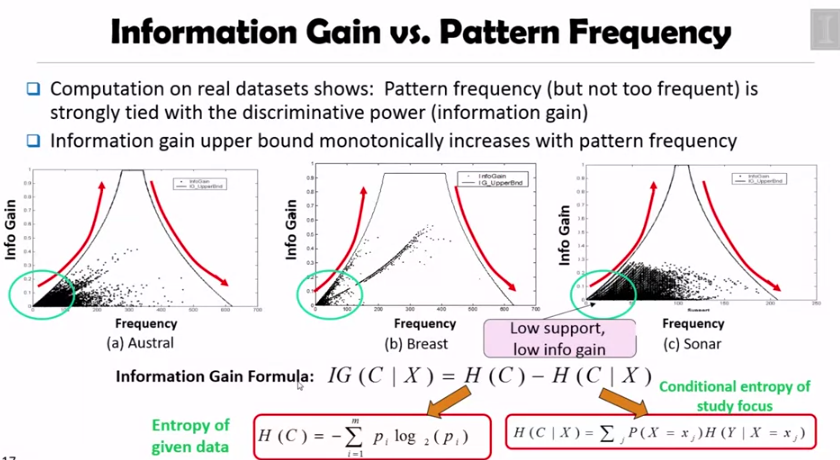
그리고 위 슬라이드에서 볼 수 있듯이, frequent, but not too frequent 한 패턴이 discriminative 하게 적용됨을 알 수 있습니다. (info gain 이 더 많다는 뜻)
DDP Mine
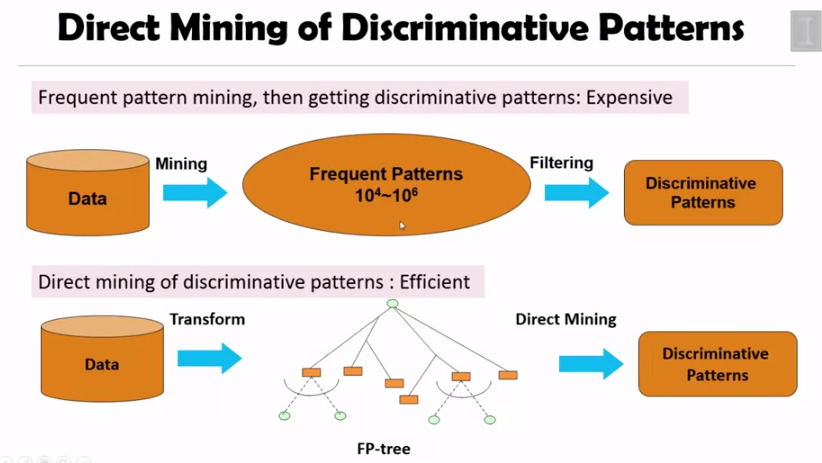
frequent pattern mining 후에 discriminative pattern 을 얻는 것은 계산적으로 비쌉니다. 따라서 바로 discriminative pattern 을 얻을 수 있습니다.

알고리즘은 이렇습니다. 매 이터레이션마다 가장 discriminative power 가 큰 feature f 를 고르고, D 에서 f 에 의해 커버 되는 인스턴스 D 를 제거합니다.

Refs
(1) Title image
(2) Pattern Discovery by Jiawei Han
comments powered by Disqus