CC 06: Multicast

multicast 는 클라우드 시스템에서 많이 사용됩니다. Cassandra 같은 분산 스토리지에서는 write/read 메세지를 replica gorup 으로 보내기도 하고, membership 을 관리하기 위해서 사용하기도 합니다
그런데, 이 multicast 는 ordering 에 따라서 correctness 에 영향을 줄 수 있기 때문에 매우 중요합니다. 자주 쓰이는 기법으로 FIFO, Casual, Total 이 있는데 하나씩 살펴보겠습니다.
Ordering
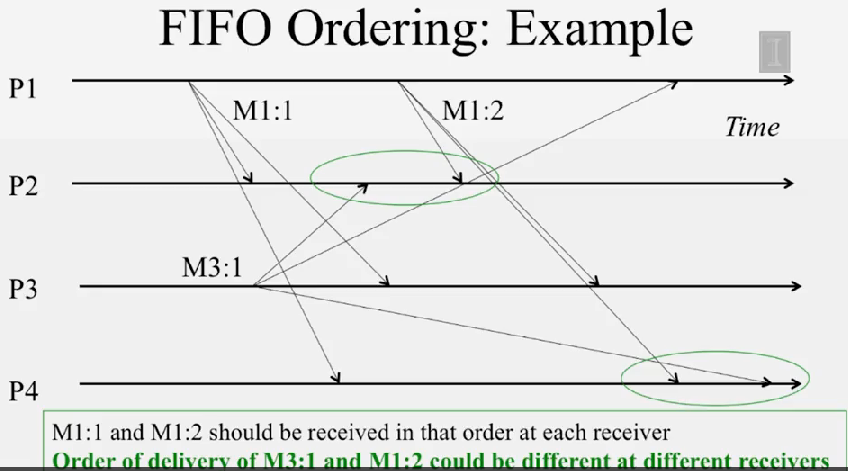
FIFO 를 이용한다면, 보낸 순서대로 도착하게 됩니다.


casual ordering 에서는 반드시 casuality-obeying order 로 전달해야 합니다. 예를 들어 위 그림에서는 M1:1 -> M3:1 이기 때문에 반드시 그 순서대로 받아야 합니다. concurrent event 는 어떤 순서로 받아도 상관 없습니다.
casual ordering 이면 FIFO ordering 입니다. 왜냐하면 같은 프로세스에서 보낸 casuality 를 따르면 그게 바로 FIFO 이기 때문입니다. 역은 성립하지 않습니다.
일반적으로는 casual ordering 을 사용합니다. 서로 다른 친구로부터 댓글이 달렸는데, 늦게 달린 친구의 댓글이 먼저 보인다면 당연히 말이 되지 않습니다.

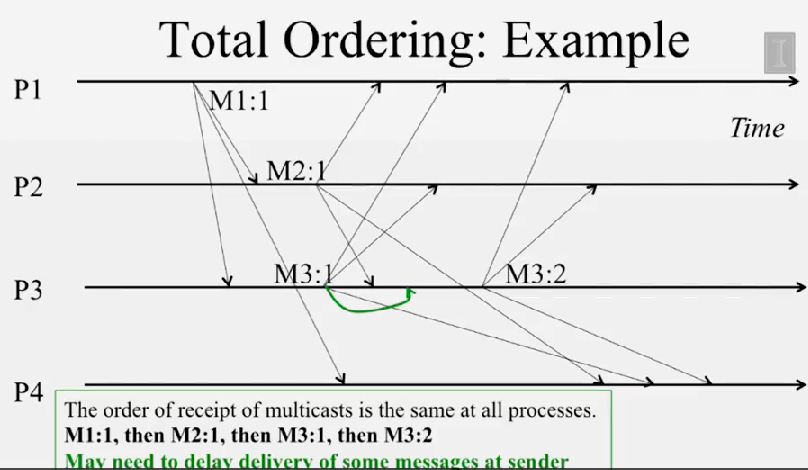
total ordering 은 atomic broadcast 라 부르는데, 모든 프로세스가 같은 순서로 메시지를 받는것을 보장합니다.
- Since FIFO/Casual are orthogonal to Total, can have hybrid ordering protocol too (e.g FIFO-total, Casual-total
FIFO Ordering Impl


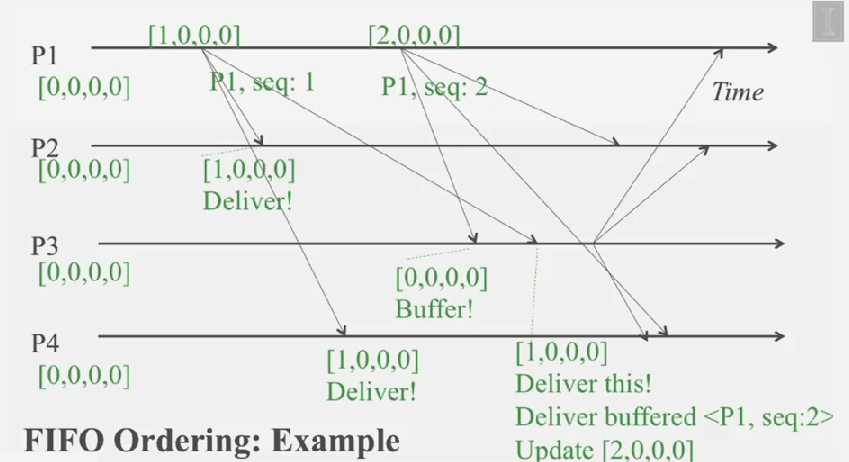
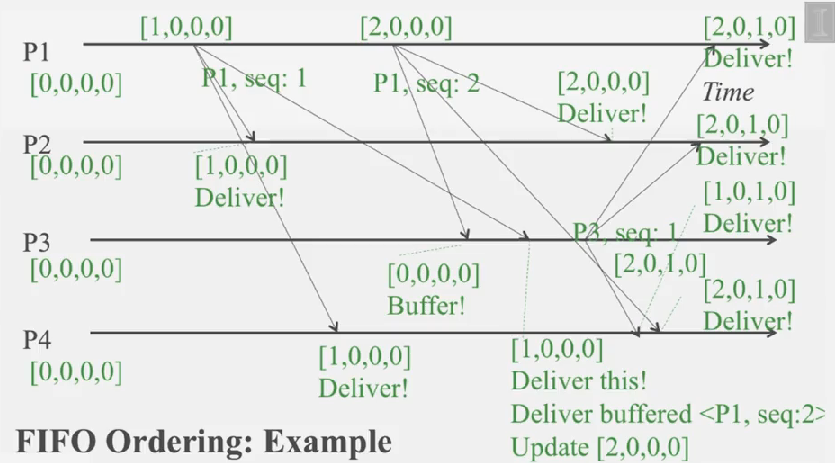
- 각 프로세스는 seq number 로 구성된 벡터를 유지하고,
- 프로세스에서 메시지를 보낼때 마다 자신의 seq number 를 하나 증가 시켜서 보냅니다
- 메시지를 받았을때, 자신의 벡터 내에 있는 값 + 1 일 경우에만 벡터 값을 +1 한뒤 전달하고, 아니면 +1 인 값이 올 때까지 버퍼에 넣고 기다립니다
예제를 보면
Total Ordering Impl

sequencer-based approach 입니다. 먼저 하나의 프로세스가 sequencer 로 선출된 뒤, 어떤 프로세스가 메세지를 보낼때마다 그룹 뿐만 아니라 sequencer 에게 보내게 됩니다.
이 sequencer 는 글로벌 시퀀스 S 를 유지하면서, 메시지 M 을 받을때마다 S++ 해서 <M, S> 로 멀티캐스트를 보냅니다.
각 프로세스에서는 local 에 글로벌 시퀀스 Si 를 유지합니다. 만약 프로세스가 메세지를 받는다면 Si + 1 = S(M) 값을 글로벌 시퀀서로부터 받을때까지 기다리고, 받은 후에야 Si++ 하고 전달합니다.
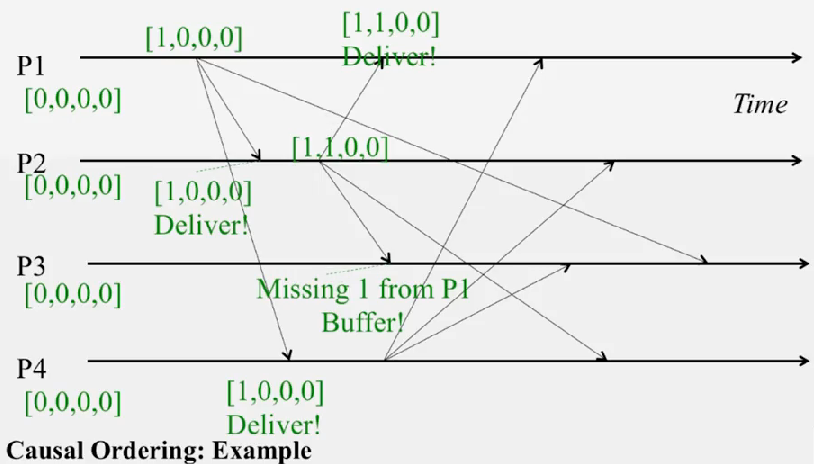
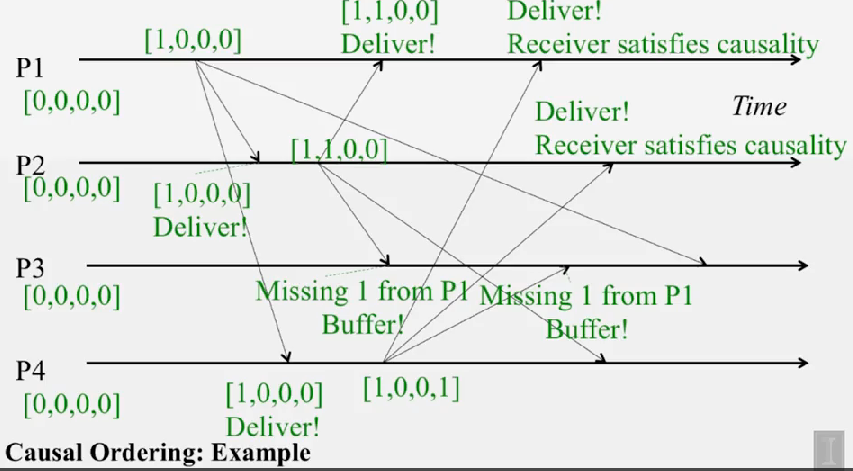
Casual Ordering Impl


자료구조 자체는 같으나, casuality 를 검사하기 위해 sender 가 vector 전체를 보냅니다. receiver 는 메세지를 받으면 다음 두 조건을 만족하기 전까지 버퍼에 넣습니다
M[j]=P_i[j] + 1M[k]<=P_i[k], (k != j)
두번째 조건을 해석하면, 자신의 벡터도 다음 프로세스에게 전달해야 하기 때문에 M[k] 이후의 벡터만 가지고 있어야 전달할 수 있다는 뜻입니다. (M[j] 는 제외)
이 두 조건이 만족되야만 P_i[j] = M[j] 로 세팅하고 M 을 전달합니다.
Reliable Multicast
reliable 이란, 루즈하게 말하자면 모든 receiver 가 메세지를 받는다는 뜻입니다. ordering 과는 orthogonal 하기 때문에 Reliable-FIFO, 등등 구현이 가능합니다. 더 엄밀한 정의는
- need all correct (non-faulty) processes to receive the same set of multicasts as all other correct processes

단순히 reliable unicast 를 여러개 보내는것 만으로는 부족합니다. 왜냐하면 sender 에서 failure 가 일어날 수 있기 때문입니다


비효율적이지만, reliable 합니다.
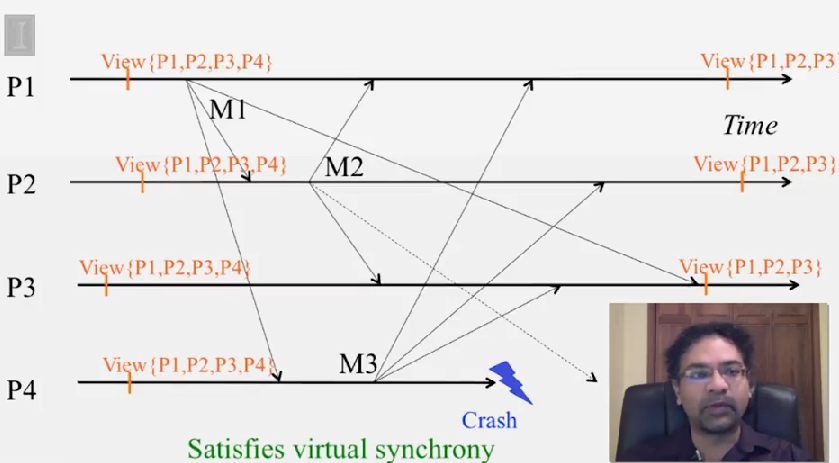
Virtual Synchrony
virtual sinchrony 혹은 view synchrony 라 불리는데, 이것은 failure 에도 불구하고 multicast ordering 과 reliability 를 얻기 위해 membership protocol 을 multicast protocol 과 같이 사용합니다.

각 프로세스가 관리하는 membership list 를 view 라 부릅니다. virtual synchrony 프로토콜은 이런 view change 가 correct process 에 올바른 순서대로 전달됨을 보장합니다.

Virtual Synchrony 프로토콜은 다음을 보장합니다.
- the set of multicasts delivered in a given view is the same set at all correct processes that were in that view
- the sender of the multicast message also belongs to that view
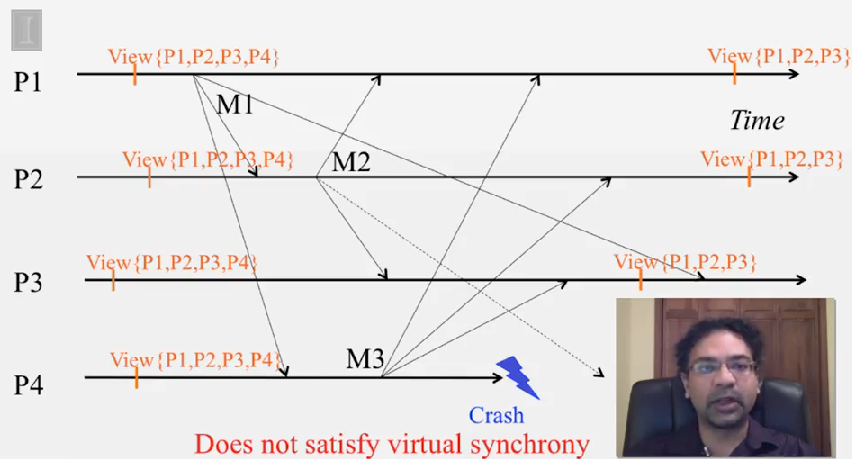
- if a process
P_idoesn’t not deliver a multicastMin viewVwhile other processes in the viewVdeliveredMinV, thenP_iwill be forcibly removed from the next view delivered afterVat the other processes
다시 말해서, multicast 메세지는 같이 전달된 view 내에 있던 다른 프로세스에서 모두 동일합니다. 그리고 view V 내에 있는 어떤 프로세스가 M 을 전달하지 못할 경우, 다른 프로세스의 next view 에서 제거됩니다.
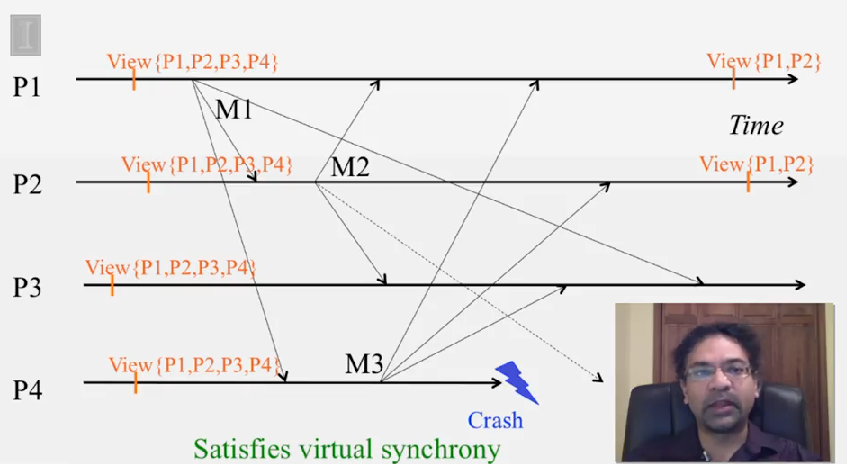
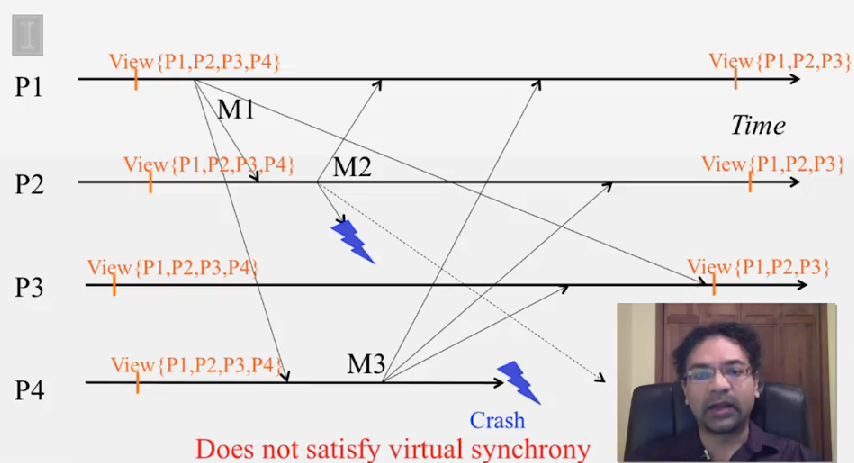
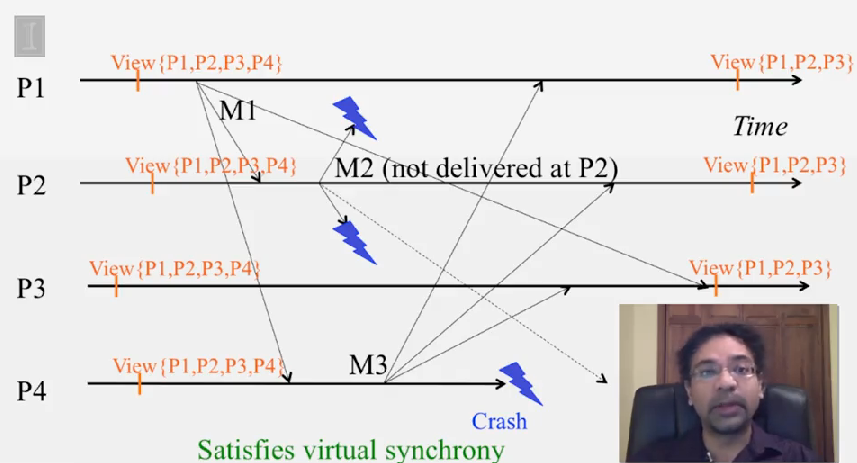
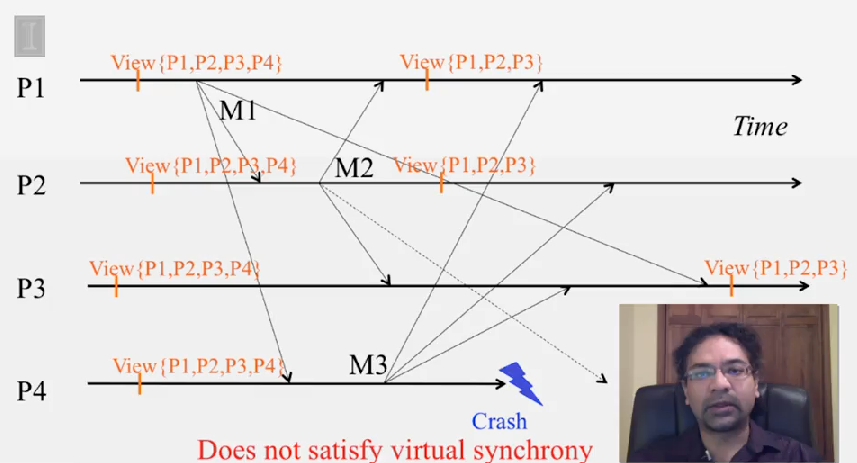
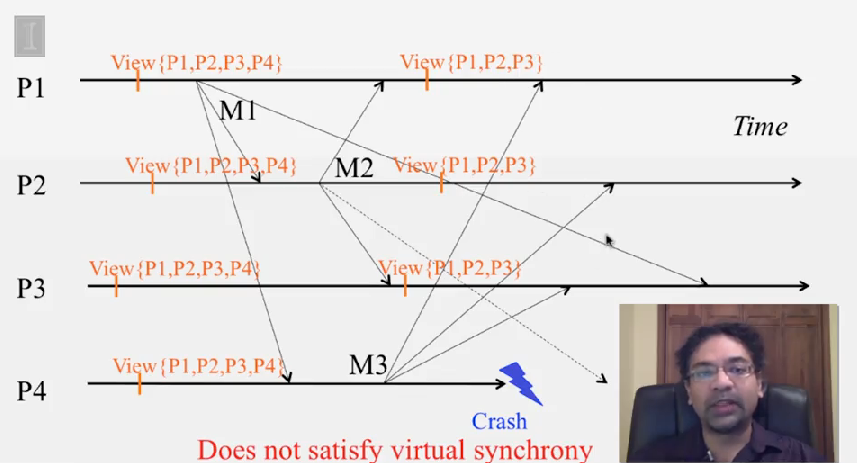
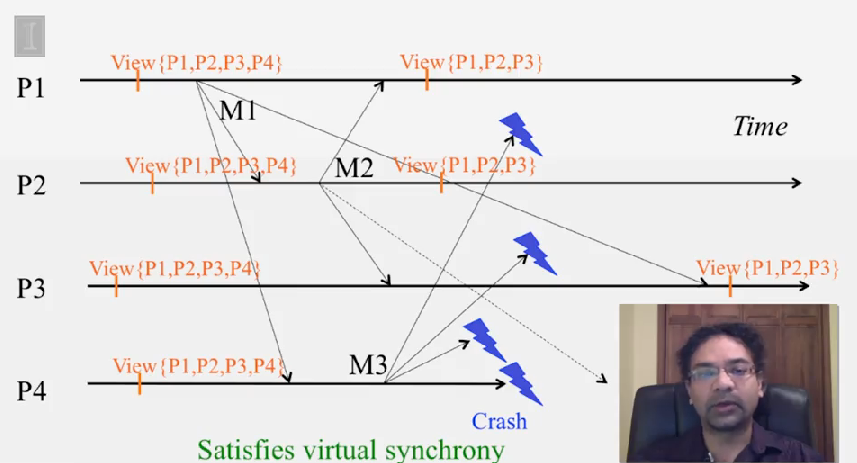
- Called “virtual synchrony” since in spite of running on an asynchronous network, it gives the appearance of a synchronous network underneath that obeys the same ordering at all processes
그러나 consensus 를 구현하는데는 쓸 수 없습니다. partitioning 에 취약하기 때문입니다.
정리하자면 multicast 는 클라우드 시스템에서 중요한 요소입니다. 필요에 따라서 ordering, reliability, virtual synchorny 를 구현할 수 있습니다.
Refs
(1) Title Image
(2) Cloud Computing Concept 1 by Indranil Gupta, Coursera
comments powered by Disqus