Design and Analysis: Divide & Conquer
Divide and Conquer (분할 정복) 을 배운다. merge, quick sort 를 배우고 이 과정에서 왜 combine 단계가 O(n) 이 되어야 하는지 알아본다. 뒷부분에서는 Big O 뿐만 아니라 master method, decomposition approach 를 이용해 성능을 분석한다.
Divide and Conquer
각 level 의 문제 갯수는 2^j (j = 0, 1, 2, ... , log2n) 이고 문제의 사이즈는 n / 2^j 이므로 연산수를 k 라 하면, 각 레벨에서 연산 수는 k * n, 레벨의 depth 가 log2n + 1 이므로,
merge sort 같은 경우는 연산수 k = 6 에서 6n (log2n + 1)
Big O 는 O(f(n)) 이라 했을때 at most, f(n) 에 proportional 하므로 upper 바운드.
반면 Omega 는 omega(f(n)) 이라 했을 때 at least f(n) 에 proportional 하므로 lower 바운드.
분할 정복의 핵심은 각 sub-problem 에서 연산 수를 o(n) 으로 맞출 수 있느냐 없느냐, 맞춘다면 nlogn 알고리즘이 되는 것이다.
알고리즘은 3단계로 구성된다.
(1) Divide
(2) Conquer sub problems
(3) combine (merge)
여기서 중요한건, combine 단계인데 이게 O(n) 이기만 하면 전체 알고리즘의 성능을 O(nlogn) 으로 보장할 수 있음.
Master Method: Motivation
T(n) 을 O(n) 으로 upper bound 를 구하긴 했지만 O(n) 연산 수 구하는게 좀 힘들다. 재귀 호출의 갯수나, 문제의 분할 사이즈로 O(n) 을 쉽게 구해보자.
가우스 곱셈? 의 경우에 T(n) <= 4 * T(n/2) + O(n)
그러나 더 작아질 수 있음. (a+b)(c+d) 에서 ad+bc = (a+b)(c+d) - ad - bd 로 구할 수 있음
즉 3개의 부분식만 구해도 됌.
T(n) <= 3 * T(n/2) + O(n)
머지소트는 2 * T(n/2) + O(n) 쯤 되니까 가우스보다 더 낫긴 함. 그럼 가우스의 그것은 얼마일까?
Master Method
Master method 는 재귀 문제의 러닝타임을 구하는데 black box 같은 역할을 한다. 대강의 코드만으로도 러닝타임을 추측할 수 있다.
그러나 master method 는 가정을 하나 하는데, 바로 모든 문제가 같은 사이즈로 분할 된다는 것.
All sub priblems have equal size
n 이 충분히 작다면, T(n) 은 상수라 볼 수 있고 만약 n 이 충분히 크다면 master method 는 다음의 포맷을 가진다.

(https://acrocontext.wordpress.com)
여기서 a 는 재귀 함수 호출의 수고, b 는 분할된 문제의 사이즈다. d 는 combine 스텝에서 사용하는 함수의 러닝타임의 지수다. (merge-sort 에서 머징하는 함수라 보면 된다.)
a: number of recursive calls (>= 1)b: input size shrinkage factor (> 1)d: exponent in running time of combine step (>= 0)
이제 몇 가지 예제를 좀 살펴보자.
merge sort 의 경우는 a = 2, b = 2, d = 1 이므로 2 = 2^1 이어서 O(n^1 * logn) 즉 O(nlogn) 의 러닝타임을 가진다.
binary search 는 문제 수가 절반으로 줄긴 하나 반쪽만 사용하고, 매 재귀호출 마다 한번의 비교만 하므로 a = 1, b = 2, d = 0 이므로 a = b^d 는 1 = 1^1 이 되어 O(nlogn) 이 된다.
가우스 곱셈은 a = 3, b = 2, d = 1 이므로 O(n^log2_3) 이 된다. 더 정확히는 O(n^1.59) merge-sort 보다 빠르진 않지만 quadratic 보단 빠르다.
strassen 행렬 곱셈은 어떨까? a = 7, b = 2, d = 2 에서 마찬가지로 case 3 이므로 O(n^log2_7) 이다. O(n^2.81) 쯤 되므로 O(n^3) 보다는 훨씬 낫다.
merge-sort 에서 d = 2 라면 O(n^2) 이 나온다. 사실 일반적으로 생각하기에는 O(n^2 * logn) 이 나올거 같은데, 사실 이건 upper bound 이므로 O(n^2) 이 좀 더 나은 upper bound 임을 알 수 있다. 이 사실은 master method 를 이용하면 수학적으로 더 근사한 값을 찾아낼 수 있다는걸 알려준다.
Proof: Master Method
재귀의 각 단계를 j = 0, 1, 2, ... , logb_n (base b) 라 하면 각 단계에서는 a^j 사이즈의 sub-problem 수와 n / b^j 사이즈의 문제가 있다.
단계 j 에서의 연산은 a^j * c * (n / b^j)^d 즉 문제의 수 x 각 문제의 사이즈와 일어나는 거기서 일어나는 연산 수 로 정의할 수 있다. 수식을 j 로 다시 정리하면
각 단계의 sub problem 에서 일어나는 연산은 c * n ^d * (a / b^d)^j 다. 따라서 전체 단계를 구하려면 여기에 시그마를 씌우면 된다.
식을 좀 더 자세히 보면
a: rate of sub problem proliferation (RSP)b^d: rate of work shirinkage (RWS)
d 가 n^d 에도 섞여있어 좀 복잡하긴 한데 느낌만 알아보자면 b = 2, d = 1 일때는 sub-problem 당 문제가 1⁄2 씩 줄어든다. 하지만 b = 2, d = 2 라면 문제의 수가 2배가 될때 문제 사이즈는 4배가 되고, b^d = 4 가 되어 1⁄4 만큼의 연산만 줄어든다. 따라서 d 가 커지는 건 생각보다 영향이 큰 걸 알 수 있다.
위 식으로부터 다음의 관계를 이끌어 낼 수 있다.
(1) if RSP < RWS, then the amount of work is decreasing with the recursion level j
(2) if RSP > RWS, then the amount of work is increasing with the recursion level j
(3) if RSP = RWS, then the amount of work is same at every recursion level j
따라서 (3) 의 경우 각 단계에서의 연산이 c* n^d * 1^j 이므로 깊이 logb_n (base b) 을 곱하면 O(n^d * logn) 이다. (a, b 는 문제의 사이즈와 관계가 없다 그리고 더 정확히는 시그마를 더하면 O(n^d * (1 + logb_n) 이다)
(2) 의 경우 깊이가 깊어질 수록 각 단계에서의 연산이 급격하게 줄어들고, 루트에서의 (j = 0) 연산이 가장 크므로 루트에서의 연산을 upper bound 로 보면 O(n^d) 라 볼 수 있다.
마지막으로 (1) 의 경우 깊이가 깊어질수록 연산이 늘어나고, 대충 생각하면 마지막 노드의 개수에 비례하는 Big O 를 가지리라는 생각을 해볼 수 있다.
좀 더 수식에 대한 이해를 얻기 위해 수학적으로 접근해 보자.
1 + r + r^2 + ... + r^k 를 귀납법으로 풀면 r^(k+1) - 1 / r - 1 이란 값이 나온다. (r != 1) 이 때
r < 1 이고 k 가 충분히 크다면 이 식은 1 / (1 - r) 이라 보아도 된다. 다시 말해서 k 와는 관련 없는 상수라 보아도 된다는 뜻이다. 그리고 첫번 째 항이 다른 것들의 합보다 크다고 볼 수 있다.
r > 1 이라 했을때, 우측 식 r^(k+1) - 1 / r - 1 은 r^k * (1 + 1 / r - 1) 보다 항상 작거나 같다는 사실을 알 수 있다 (upper bound) 다시 말해서 마지막 항 r^k 의 2배보다 작거나 같다는 사실을 알 수 있다. 이것도 r = 2 일때나 맥시멈 두배다.
1 부터 256까지 더해봐도 512 보다 작거나 같다는 사실을 알 수 있다. 다시 말해서 마지막 항이 그 전 모든 항을 합한 것 보다 크다.
이제 다시 master method 로 다시 돌아오자.
c* n^d * sigma(j) (a / b^d)^j (j = 0 to logb_n) 에서 a / b^d 를 r 이라 두자.
RSP < RWS (case 2) 이면 r < 1 이므로 시그마를 합해봐야 특정 상수다. O(n^d)
반대로 RSP > RSW (case 3) 이면 r > 1 이므로 시그마를 합해봐야 r^k * 상수 보다 작거나 같으므로 가장 큰 항 r^k 는 (a / b^d)^logb_n 이다. 여기서 b^(-dlogb_n) 이 n^-d 라는 사실을 이용하면 O(a^logb_n)만 남는다.
그런데, 재미있는 사실은 logb_n 이 마지막 단계이고, a 는 각 단계에서 분할되는 노드의 갯수이므로 a^(logb_n) 은 recursion tree 에서 leave 의 갯수다.
다시 말해서 마지막 단계에서의 노드의 갯수에 연산이 비례한다. 근데 처음에 우리가 봤던건 n^(logb_n) 아니었던가? 사실 로그를 배우면 위 두 식은 같다는걸 알 수 있다.
Quick Sort
퀵소트는 평균적으로 O(n logn) 성능을 보여주며 in-place 로 작동하는 인기있는 정렬 알고리즘이다.
key idea 는 pivot 을 중심으로 문제를 좌우로 분할하는 것이다. less than pivot 들은 왼쪽에, greater than pivot 들은 우측에 놓음으로써 최소한 한번의 분할당 하나의 원소 (pivot) 은 자리를 잡는 다는 것을 보장한다.
퀵소트의 매 호출당 일어나는 partition (분할) 은 다음의 두 특징을 가진다.
(1) linear time, O(n)
(2) no extra memory
대강의 로직은 이렇다. Quicksort(array A, length n) 에 대해서
(1) if n = 1 return A
(2) p = choose Pivot(A, n)
(3) partition A round p => L, R
(4) recursively solve L, R
보면 알겠지만 combine 혹은 merge 스텝이 전혀 없다.
Partition: In-place
O(n) 의 추가 메모리를 사용하면 연산시간 O(n) 을 구현하기 쉽다. 추가 메모리 없이 어떻게 O(n) 으로 partitioning 을 구현할 수 있을까?
(1) 첫 번째 원소를 pivot 이라 놓고
(2) pivot 다음의 원소를 i, j 가 가리키게 한다.
(3) j 보다 작은 원소들은 partitioned , 큰 원소는 unpartitioned 라 보고
(4) i 보다 작은 원소들은 pivot 보다 작은 값, 큰 원소들은 pivot 보다 큰 값이다.
(5) i <= j 이며, i == j 일때는 j 값을 증가시켜 원소를 비교 한뒤 j 에 있는 원소가 i 가 가리키는 원소보다 크면 swap 하고 i += 1, j +=1 아니면 j += 1 한다.
이해가 쉽게 그림을 첨부하면


(http://sadakurapati.wordpress.com)
이런 로직으로 n 개의 원소를 순회하면, n-1 번 만큼 j 순회를 하고 최악의 경우 n-1 번의 swap 과 i += 1 연산이 일어난다. 다시 말해 각 원소마다 O(1) 연산이므로, partition 연산은 O(n) 이라 보장할 수 있다.
quick-sort 는 귀납법으로 증명하기도 쉬운데, P(n) 이 1부터 n 까지의 정렬된 원소를 가지고 있는 배열이라고 하면,
P(1) 임은 자명하고, 문제의 수 k 에 대해 퀵소트가 P(k) 일때 P(k+1) 임을 보이면 P(n) 에 대해서도 참임을 알 수 있다.
그런데, P(k+1) 에서 pivot 을 제외한 좌측과 우측의 사이즈를 k1, k2 라 하면 k1, k2 < k 이다. 좌측 또는 우측이 없을 때라야 k1 or k2 = k 다. 이때 P(k) 가 참이므로 이보다 작거나 같은 k1, k2 의 문제 사이즈에 대해서도 참이다. 따라서 P(k+1) 도 참이다.
Choosing a good pivot
그럼 pivot 은 무엇을 기준으로 잡는게 좋을까? 어차피 비교에서 i != p and j != p 라면 구현에는 어느 위치에 잡던 문제가 없을것 같은데..
만약에 pivot 이 첫 번째 원소이고, 입력이 이미 정렬이 된 배열이라면 성능이 어떻게 될까? 바로 O(n^2) 이다. 왜냐하면 이미 정렬이 되어있으므로 문제가 1⁄2 로 분할되지 않기 때문이다. 배열 사이즈만 1씩 줄어들면서 재귀호출이 반복된다.
그럼 만약에, pivot 을 원소들의 median (중앙값) 으로 고른다면? 매 재귀마다 문제가 좌우로 분할되므로 O(nlogn) 이라 볼 수 있다.
근데 생각해 볼 거리가 있다. pivot 을 구하는 함수의 비용은 어떻게 되는걸까? 이것 또한 O(n) 이므로 전체 partition 의 비용은 O(n) 이라 보아도 된다.
Randomized pivots
그럼 만약에 pivot 을 무작위로 고르면 어떻게 될까 생각해 보자. pivot 을 무작위로 선택했을 때 한쪽이 25-75% 로 분할될 확률은 1⁄2 이다.
그리고 무작위로 pivot 을 선택했을때 첫번째 다음 재귀 호출에 넘겨질 배열의 길이의 기대값을 구하면, 다시 말해 X 를 subproblem size 라 했을때 E(X) 를 구하면
1/n * (0 + 1 + ... + (n - 1)) = (n - 1) / 2 다.
여기서 잠깐 중요한 속성인 linearity of expection 을 설명하면
모든 random variable
X의 합의 기대값은, 각X의 기대값의 합과 같다.
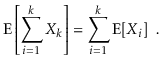
(http://www.opendatastructures.org)
Xj(i)P(i) 를 컬럼의 개수가 j, 행의 개수가 i 인 행렬의 원소로 보면 이 linearity of expectation 은 쉽게 이해할 수 있다. 이 속성은 꽤나 유용하다.
예를 들어 두개의 주사위를 독립적으로 굴린다고 할 때 나오는 값인 random variable X1, X2 에 대한 기대값을 직접 구하려면 36개의 sample space 를 살펴봐야 하는데, 그러지 말고 하나를 굴렸을때의 값을 구해 이걸 2배 하면 된다. 하나를 굴렸을때는 6개의 sample space 만 살피면 되니 금방 구한다.
로드 밸런싱문제에 linearity of expectation 을 적용해보자. n개의 서버가 있고 여기에 n 개의 프로세스를 랜덤하게 할당할때 한개의 서버에 할당될 프로세스의 기대값은 얼마일까? 다시 말해 평균적으로 몇개의 프로세스가 서버에 할당될까?
sample space 는 n 개의 항끼리의 곱에서 항의 개수를 구하는 문제와 같으므로 n^n 이다.
이때 Y 를 첫 번째 서버에 할당된 프로세스 수의 합이라 하면 이때 Y 는 sigma Xj (j = 1 to n, Xj = 1 or 0)이다.
E[Y] 를 구하는 것이 본래의 문제인데 가능한 Y 값을 모두 구한 뒤에 각각의 확률을 곱해서 더하느니, Y 를 분해해 각각의 기대값을 구한 후 더하는게 훨씬 빠르다. (주사위 굴리기 문제처럼)
다시 말해서, Y 가 여러개의 항으로 구성될때는 각각의 기대값을 구하는게 더 계산이 빠르다는것이 lineariry of expectation 의 본질이다.
따라서 기대값을 시그마 뒤쪽으로 빼서 계산하면 1 이 나온다. 다시 말해 서버 하나당 평균적으로 1개의 프로세스를 가진다는 이야기.
다시 이 확률 테크닉을 randomized pivot 을 선택하는 merge sort 에 적용하러 가 보자.
Decomposition Principle
일단 랜덤 피벗을 가지는 퀵소트를 master method 로는 Big O 를 찾을 수가 없다는 사실을 알아 두자. 이는 입력한 배열이 일정하게 분할되지 않고 피벗때문에 랜덤하게 분할되지 때문이다.
이제, 퀵 소트의 각 재귀에서 일어나는 연산 중 comparison (비교) 가 다른 연산보다 dominant 하다고 하면, 다시 말해서 비교하는 숫자에 의해 연산 수가 결정된다고 하자. 이건 생각해보면 사실인데, partition 과정에서 일어나는 비교가 각 sub-problem 에서의 연산 수를 결정한다.
이렇게 하면 연산수의 기대값, 다시 말해서 비교가 일어나는 회수의 평균으로, 퀵소트의 평균 성능을 찾아낼 수 있다.
그런데 입력 배열에 대한 전체 비교 수를 C 라 두면 E(C) 는 사실 구하기가 굉장히 어렵다. 그런데, E(C) 를 시그마 두번으로 분해할 수 있고, 심지어 가장 내부의 항은 1 또는 0 을 가지는 원소이다. 따라서 linearity of expectation 을 이용할 수 있다 할렐루야
참고로 가장 내부의 항에 대해서 설명하자면, 전체 입력에서 두개의 원소를 골랐을 때 이 두개의 원소가 비교 되는 수다. 이 두개의 원소는 i, j 를 기준으로 구할 수 있으므로 X_ij 라 두면 i, j 에 각각에 대해 시그마를 씌울 수 있다. 이것이 C 이므로 E(C) 를 구하기는 상당히 복잡함을 알 수 있다. 그런데 X_ij 자체는 0 또는 1 만 가지는 값이니 이것에 대해 E(X_ij) 를 구하면 심플해진다. (수식을 적기 힘드니 자세한 내용은 강의 Analysis I: A Decomposition Principle 을 참조)
따라서 E(C) 는 sigma i <- 1 to n-1, sigma j <- i+1 to n P(X_ij = 1) 이다.
여기서 잠깐 이제 까지 나온 decompositio principle 을 설명하자면
(1) 구하고자 하는 랜덤 변수 Y 를 정의하고
(2) Y 를 더 간단한 랜덤 변수 X 의 합으로 정의하자. X 가 0 또는 1만 가지는 값이면 더 좋다.
(3) linearity of expectation 을 적용
다시 말해 알고리즘의 성능을 결정하는 dominant operation 을 확률변수로 표현할 수 있고, 더 간단한 확률 변수의 합으로 표현할 수 있다면 해해 여기에 기대값의 선형성 을 이용해 알고리즘의 평균적인 성능을 구할 수 있다는 뜻이다.
sigma i <- 1 to n-1, sigma j <- i+1 to n P(X_ij = 1) 다시 이 식으로 돌아오자. 여기에 적용할 수 있는 퀵소트의 특징이 있다. 여기서 z_i 를 정렬된 배열의 i 번쨰 원소라 했을때 pivot 이 될 수 있는 것은 z_i, z_i+1, ... z_j-1, z_j 다. 이때
(1) z_i 또는 z_j 가 pivot 이 되면, 즉 가장 작은 수나 가장 큰 수가 pivot 이 되면 z_i 와 z_j 는 한번만 비교된다. (이후에는 다른 재귀로 넘어가 둘 중 하나의 수만 남음)
(2) z_i+1, …, z_j-1 이 pivot 이 되면 z_i 와 z_j 는 절대로 비교되지 않는다. pivot 기준으로 큰 수와 작은수는 서로 비교되지 않으며 둘 다 피벗과만 비교된다. 이후에도 다른 파티션으로 나누어져 비교되지 않는다.
따라서 각 sub-problem 에서 일어나는 비교가 일어날 확률은 2 / (j - i + 1) 이다. 다시 말해서 전체 원소 중에서 z_i 와 z_j 를 피벗으로 삼는 경우에만 비교가 일어난다.
따라서 평균 연산 수 E(C) 는 sigma i <- 1 to n-1, sigma j <- i+1 to n [2 / (j -i + 1)] 이다.
이때 j = i +1 부터 시작하므로 내부 시그마는 1/2 + 1/3 + ... 1/n 이다. 그리고 내부 시그마에서 i 가 사라졌으므로 외부 시그마 i <- 1 to n-1 을 n-1 대신 대략 n 이라고 놓으면,
E(C) <= 2 * n * [sigma k <- 2 to n (1/k)] 다.
이때 sigma k <- 2 to n (1/k) <= ln n 인데, 본래 식의 k 1 부터의 시그마보다 작으므로 이걸 적분으로 넓이를 구하면 ln n - ln 1 = ln n 이다.
따라서 E(C) <= 2 * n * ln n
Notes
이하는 필기 노트입니다.
matrix multiplication
단순히 brute force 로 3 for-loop 로 구현하면 당연히 o(n^3) -_-;
스트라센 매트릭스 곱셈으로 구현하면 놀랍게도 n^2
Multiplication
- define Input, output
- assess performance
can we do better strait forard?
일반적인 곱셈(초등3학년)은 2n * n
Karatsuba Multiplication
a * c b * d = 2652 (a + b)(c + d) = 6164 (a+b)(c+d) - a*c - b * d = 2840
ad bc
6164 + * 10000 + 2652 + 2840 * 100
x = 10^n/2 a + b y = 10^n/2 c + d
x * y => 10^n ac + 10 n/2 (ad+bc) + bd 따라서 Karatsuba multiplication 은 product 문제를 ac, ad, bc, bd 의 곱으로 쪼갬.
여기서도, ac, ad, bc, bd 를 모두 구하는 대신에
(a+b)(c+d) - ac bd 를 빼면, ac bd (a+b)(c+d) 3개만 구하면 된다.
따라서 3개의 recursive multiplication 만 필요
Closest Pairs
brute force 는 n^2 인데,
1D 의 closest pair 에서 sorting 하면 n^2 가 아니라 nlogn 이다.
로직은 다음과 같다.
문제를 반으로 잘라가면서 왼쪽에서 거리가 가장 짧은것 좌표 쌍, 오른쪽에서 가장 짧은것을 찾고, 각 영역에 좌표가 하나씩 있는 쌍도 검사 한다.
(1) 주어진 배열을 P 라 하고 반으로 각각 좌우 Q, R 자른다. O(n) Q를 x 정렬한것을 Qx, y 축 기준으로 Qy, R도 Rx, Ry. 이건 전체 인풋 n 에 대해서 n logn
(2) ClosestPair(Qx, Qy), Closest(Rx, Ry) 해서 각각 좌 우에서 가장 짧은 거리를 가진 pair 쌍을 찾는다. 이걸 (p1, q1), (p2, q2) 라 하면
(3) (p1, q1), (p2, q2) 의 거리를 구해 최소값인 d 를 찾는다
(4) Closest(Px, Py, d) 해서 (p3 , q3) 가 있으면 찾아낸다. 여기서 찾은건 하나는 Q 하나는 R 에 있는 d 보다 작은 거리를 가진 점의 쌍
(5) p1, p2, p3 쌍중 가장 작은 d 를 가진 것을 리턴
ClosestSplitPair
(1) Px 의 가운데 점을 xBar 라 하면 이것 기준으로 -d, +d 의 x 값을 가진 점들을 Py 에서 찾아낸다. 정의에 의해서 x1 - x2 <= d 이기 때문에 아무리 커봐야 xBar 기준으로 좌우 d 까지밖에 존재하지 못함. 이걸 Sy 라 부르자. 이건 Py 가 이미 정렬되어 있기 때문에 O(n) 시간.
(2) Sy 는 y 축 기준으로 이미 정렬되어 있는데, 여기서 Sy 의 원소를 루프로 돌면서 이것 기준으로 +7개 원소를 검사하면서 거리가 d 보다 작은것이 있는지 검사. 이것 또한 마찬가지로 d 의 정의와 두 점이 Q, R 에 있다는 점을 이용해서 증명이 가능함.
y1 - y2 도 d 보다 작거나 같이 때문에 y 기준으로 정렬된 점을 기준으로 잡았을때,
p 와 같은 왼편에 있는 것들은 p와의 거리가 d 보다 작을 수 없다. 왜냐하면 d 자체가 같은 사이드에 있는 것들의 최소 거리이기 때문. 이런점들을 아무리 많이 왼쪽에 구겨 넣어도 3개. p 포함하면 4개다. 마찬가지로 q 와 같은 편에 있는것들도 3개.
따라서 운이 나쁠 경우 Sy 에서 p, q + 6개를 더 검사해야.
직사각형을 그려보면 이해가 쉬움.
Input 은 (x1, y1) … (xn, yn) 의 pair n개 편의상 p1, p2, … pn
d(p_i, p_j) 는 두 point 사이 거리
(1) 모든 점들을 x 기준으로 정렬했을때 가운데에 있는 점을 xBar 라 하면 S_y 는 xBard - d, xBar + d 사이에 있는 모든 점이다. 만약에 왼쪽에 있는 p, 오른쪽에 있는 q 가 존재한다면 이 둘은 S_y 사이에 있고 아래 증명에 에해서 x1, x2 사이 거리는 d 보다 작다.
왜냐하면, p(x1, y1), q(x2, y2) 사이의 거리가 d 보다 작기 때문에 x1 - x2 <= d 이다.
(2) S_y 에서 p, q 가 존재한다면 그건 y 기준으로 7 원소 이내에 인접해 있다.
References
(1) https://acrocontext.wordpress.com
(2) http://sadakurapati.wordpress.com
(3) http://www.opendatastructures.org
comments powered by Disqus