CC 03: Membership Protocol

왜 membership 이란 개념이 클라우드 컴퓨팅에 필요할까요?
한 노드가 OS, Disk, Network 등 때문에 10년 (120개월) 마다 한 번씩 고장난다고 합시다. 그러면 120개의 노드를 가지고 있다면 1개월마다 한 번씩입니다. 이정도는 참을만하죠? 그런데, 12,000 개의 서버를 가지고 있다면 MTTF (mean time to failure) 는 7.2 시간마다 한번씩입니다. 이건 큰 문제입니다.
따라서 머신이 멀쩡한지 아닌지를 수동이 아니라 자동으로 판단하고 보고해줄 시스템이 필요합니다. membership 이 필요한 것이죠. 이 대상은
(1) Process group-based systems
- Clouds / Datacenters
- Replicated servers
- Distributed databases
(2) Cash-stop / Fail stop process failures
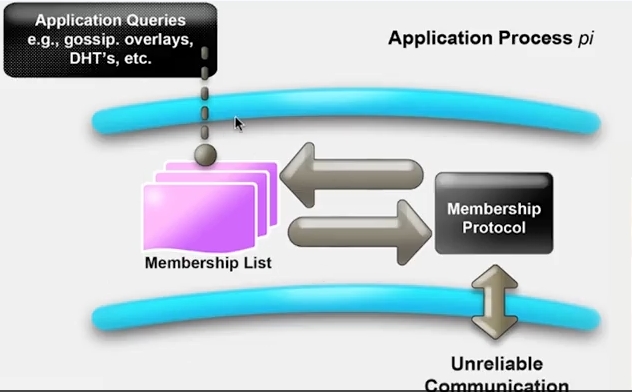
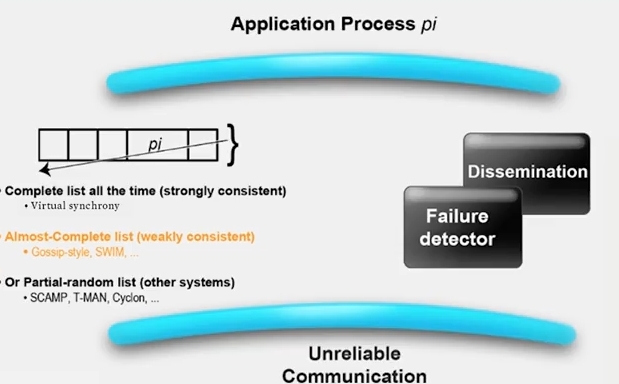
멤버십 프로토콜은 다음처럼 구성되어 있습니다.
- 멤버쉽 리스트 (complete, almost-complete, partial-random)
- dissemination mechanism to inform about joins, leavs, and failures of processes
- failure detector
Failure Detector
distributed failure detector 를 평가할 수 있는 지표는
- Completeness: each failure is detected
- Accuracy: there is no mistaken detection
- Speed: time to first detection of a failure
- Scale: equal load on each member. network message load
안타깝게도 completeness 와 accuracy 를 lossy network 에서 동시에 추구할 수 없다는 사실이 밝혀졌습니다. (Chandra and Toueg)
현실적으로는
- completeness: 100% guaranteed
- accuracy: partial / probabilistic guarantee
(1) Centralized Heartbeating
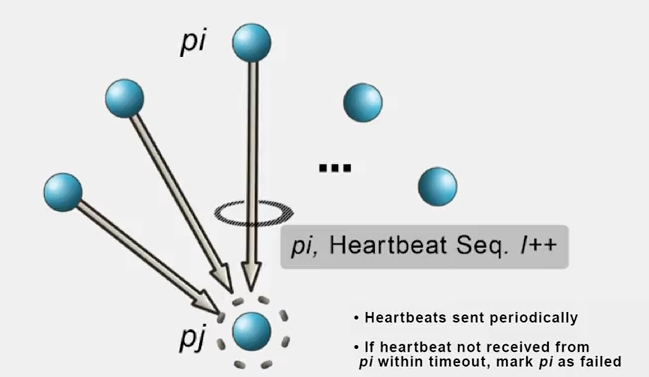
중앙 집중형이기 때문에 load 가 한쪽으로만 쏠린다는 단점이 있습니다.
(2) Ring Heartbeating
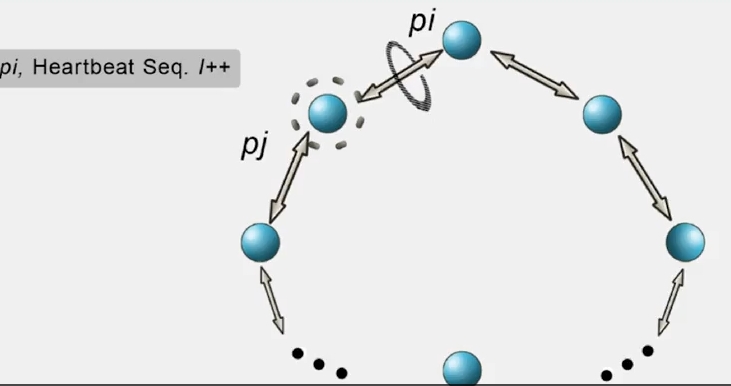
링 형태로 구성되었기때문에 동시에 발생하는 다수개의 failure 를 탐지하지 못합니다.
(3) All To All Heartbeating
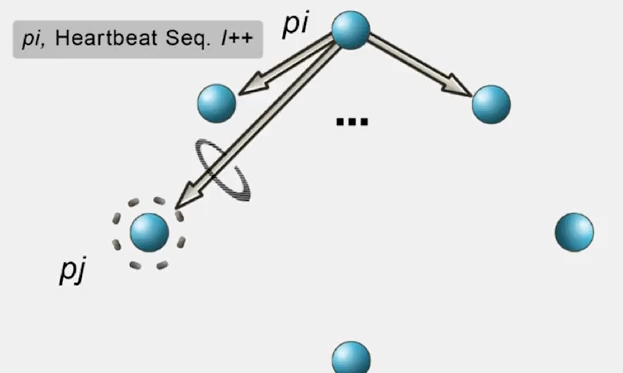
우선 equal load 라는 장점이 있습니다. 개별 노드당 오버헤드가 큰 것처럼 보이는데, 뒤에서 다시 한번 보겠지만 사실 그렇게 크지 않습니다.
(4) Gossip-Style Membership
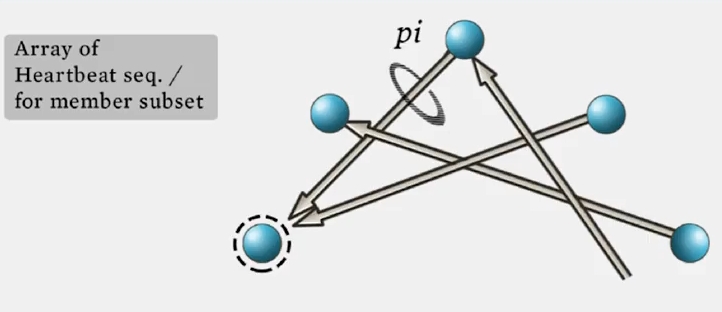
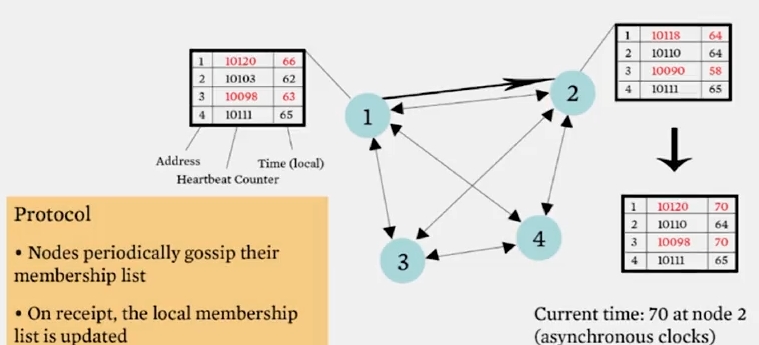
accuracy 가 높다는 장점이 있습니다.
동작 방식은 이렇습니다. hearbeat 가 T_fail 초 후에도 증가하지 않으면, 해당 멤버는 failure 를 일으킨 것으로 판별됩니다. 그리고 멤버 리스트에서는 T_cleanup 초 후에 제거됩니다.
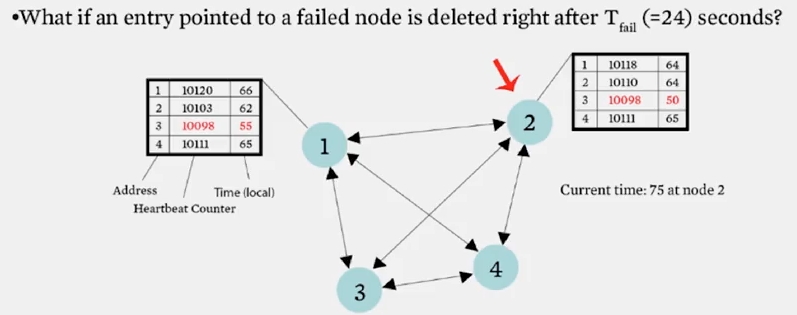
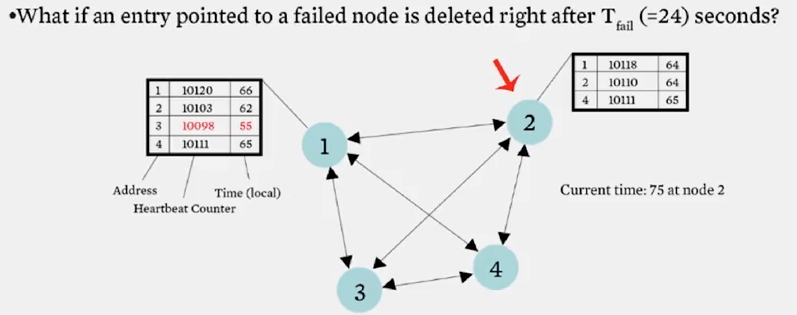
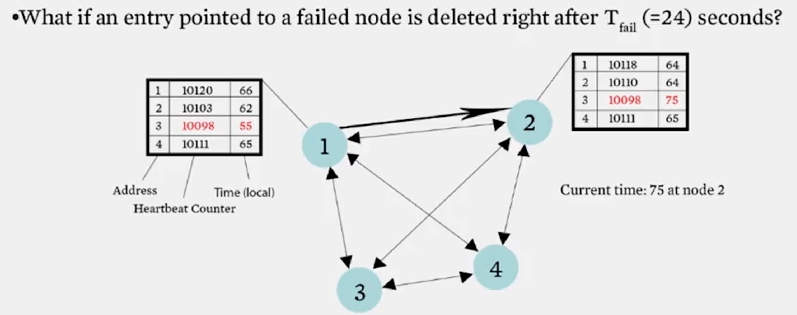
왜 바로 제거하지 않고, T_cleanup 초 후에 제거할까요? 이는 위 슬라이드에서 볼 수 있듯이 3 번 노드가 failure 를 일으켰을때, 2 번 노드의 멤버 리스트에서 바로 제거한다면 1 번 노드로부터 업데이트를 받아 멤버 리스트에 failure 가 발생하지 않은것처럼 추가될 수 있기 때문입니다.

T_gossip 이 줄면, bandwidth 를 많이 잡아먹는 대신, detection time 이 줄어듭니다. trade-off 라 보면 되겠습니다.
그리고 T_fail, T_cleanup 이 증가하면 false positive rate 는 줄어드는 대신, 당연히 detection time 이 늘어납니다.
그러면 위에 나온 것 중 어느것이 가장 좋은 failure detector 일까요? 앞서 언급했던 기준들을 이용해서 살펴보겠습니다.
- Completeness: guarantee always
- Accuracy: a prob of mstake in time T
PM(T) - Speed:
Ttime units - Scale:
N*LCompare this across protocols
(1) All-To-All Heartbeating
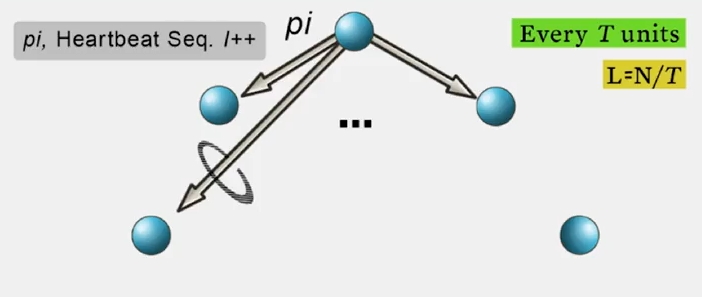
work load 가 N 에 비례합니다.
(2) Gossip-Style Heartbeating
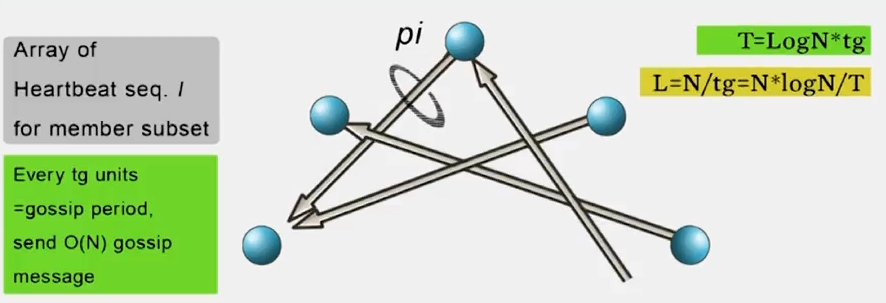
tg 를 O(n) 의 gossip message 를 보내는데 걸리는 gossip period 라 했을때, 한 round 에서의 전파 시간인 logN 을 곱해 T = logN * tg 입니다. 이때 오버헤드 L = N/tg 이므로, L = N * logN / T 입니다.
오버헤드가 all-to-all heartbeating 보다 훨씬 높죠? 이는 accuracy 가 더 높기 때문입니다. 앞에서 all-to-all 가 더 비용이 많이 들것 같지만 실제로는 그렇지 않다고 했었는데, 이런 이유에서입니다.

- worst case load per member
L*라 하고 P_ml을 독립적인 메시지 손실양 이라고 했을때,
L* 을 T, PM(T), P_ml 의 함수로 표시하면
메시지 손실 P_ml 이 높을수록, 오버헤드 L* 는 당연히 작아져야 하고, PM(T) 가 높을수록 false-positive 가 많으므로 오버헤드가 높습니다. 수식을 보면 변수 N 이 없는데, 이는 scale-free 함을 보여줍니다.
그리고 all-to-all 이나 gossip-based 는 suboptimal 입니다. 왜냐하면
L = O(N/T)- try to achieve simultaneous detection at all processes
- fail to distinguish failure detection and dissemination components
따라서 두개의 컴포넌트를 분리하고, non heatbeat-based failure detection 을 이용하면 됩니다.
SWIM Failure Detector
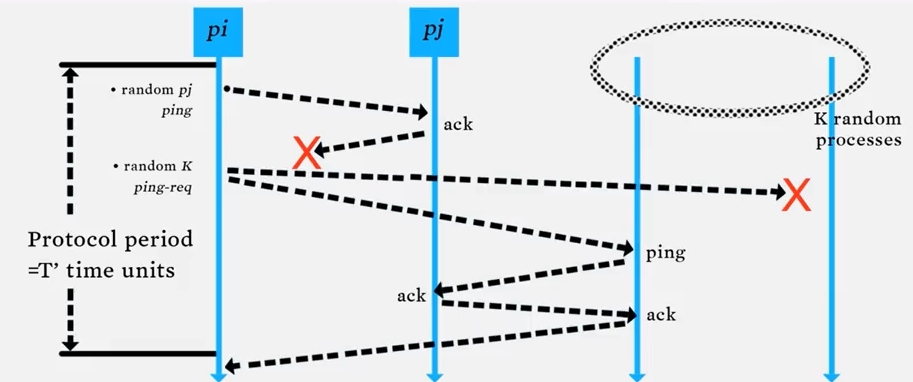
SWIM 은 probabilistic failure detector protocol 입니다.
period T 동안 프로세스(노드) pi 는 pj 를 랜덤하게 골라 ping 을 보냅니다. ack 가 오면, 남은 period 동안 아무것도 하지 않습니다. 그러나 위 슬라이드에서 볼 수 있듯이 pj 가 응답하지 않으면 랜덤하게 K 개의 프로세스를 선택해서, ping 을 날리고, 이를 통해 indirect 한 방법으로 pj 의 응답을 검사합니다.
SWIM 의 퍼포먼스는 heartbeat 와 비교했을때 어떨까요?
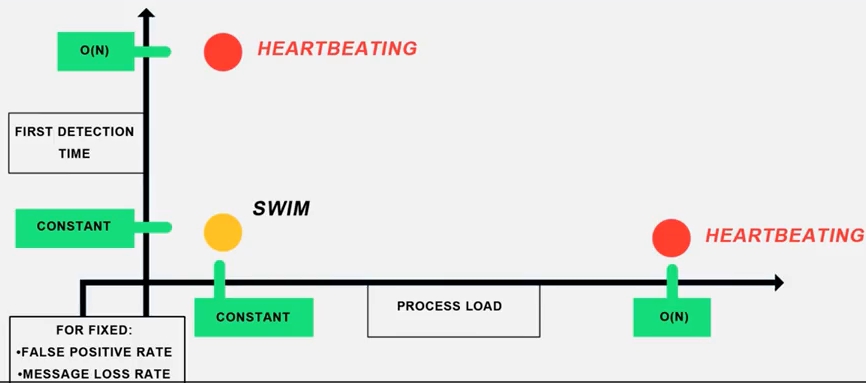
X 축은 process load, Y 축은 first detection time 입니다. false-positive rate 와 message loss rate 는 고정되어있다고 가정합니다.
heartbeat 의 경우에는 앞서 봤듯이 detection time 읖 높이면 work load 가 낮아지고 (= low bound on the bandwidth), 반대로 detection time 을 낮추면, work load 가 높아집니다. 반면 SWIM 은 둘다 적죠.
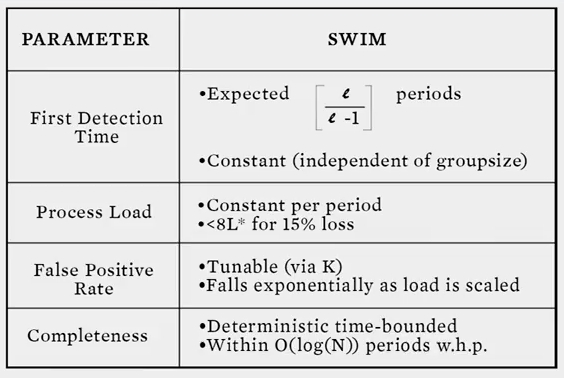
슬라이드에서 볼 수있듯이 first detection time, process load 는 constant 입니다. process load 의 경우에는 15% packet loss 가 있을때 optimal 의 8배인 8L* 보다 적습니다.
false positive rate 는 K 를 증가시켜서 줄일 수 있습니다. K 가 증가함에 따라 false positive rate 는 지수적으로 감소합니다.

쿨하게 페이퍼를 보시라는 교수님

어째서 expected detection time 이 1 / e-1 일까요? 하나의 프로세스가 죽었을때, 핑 되려면 다른 프로세스의 멤버쉽 리스트에 있어야 하고, 랜덤하게 선택되야 합니다.
랜덤하게 선택될 확률은 1/N 이고, 선택되지 않을 확률은 1 - 1/N 입니다. 다른 N-1 개의 프로세스에 의해 모두 선택되지 않을 확률은 (1-1/N)^N-1 이고, 1 에서 이 값을 빼면 선택될 확률입니다. 그리고 익히 알려진 바대로 응? N 이 매우 커지면 이 값은 1-e^-1 과 같습니다.
그리고 확률론을 잘 안다면 응? 이 값에 기대값을 취하면 e / e-1 이 됩니다.

여기에 간단한 트릭을 이용하면 worst case 로 O(N), 정확히는 2N-1 period 내에 failure 가 발견되도록 할 수 있습니다. membership list 를 순회하다가, 마지막에 도달하면 랜덤하게 재배열 하는 것입니다.
그러면 최악의 경우 2번째 멤버에 대해 ping 을 날릴때 첫번째 멤버에 failure 가 발생하고, 재 배열했을때 첫번째 멤버가 마지막에 있다면 (N-1) + (N) 의 period 가 걸립니다. 그리고 이것은 accuracy 등 다른 failure detector 의 속성들을 그대로 유지한채 worst case 시간을 줄이는 결과를 만듭니다.
Dissemination and Suspicion
dissemiantion 방법으로
(1) Multicast (Hardware / IP)
- unreliable
- multiple simultaneous multicasts
(2) Point-To-Point (TCP / UDP)
- expensive
(3) Zero extra message: Piggyback on Failure Detector messages
- Infection-style Dissemination (like SWIM)

슬라이드에서 볼 수 있듯이 infection style dissemination 은 λ log(N) protocol periods 후에 N^-(2λ-2) 개의 프로세스만 업데이트되지 않습니다. 바꿔말하면 O(logN) 후에 대부분의 프로세스는 발견돈 failure 정보를 업데이트 한다는 뜻입니다.
여기서 λ 는 consistency level 을 결정하는 상수입니다. 어떤 경우에도 SWIM detector 는 failure 를 2N-1 내에 발견하기 때문에 completeness 100% 가 보장됩니다.
Suspicion Mechanism
false positive 가 발생하는 이유는
- perturbed processes
- package losses (e.g from congestion)
SWIM 에서 사용했던 indirect pinging 도 이 문제를 해결하지 못할 수 있습니다. (e.g correlated message losses near pinged host)
먼저 failure 가 발견되었을때 다른 노드들에게 알리기 전에 먼저 suspect 한다면 false positive 비율을 줄일 수 있습니다.
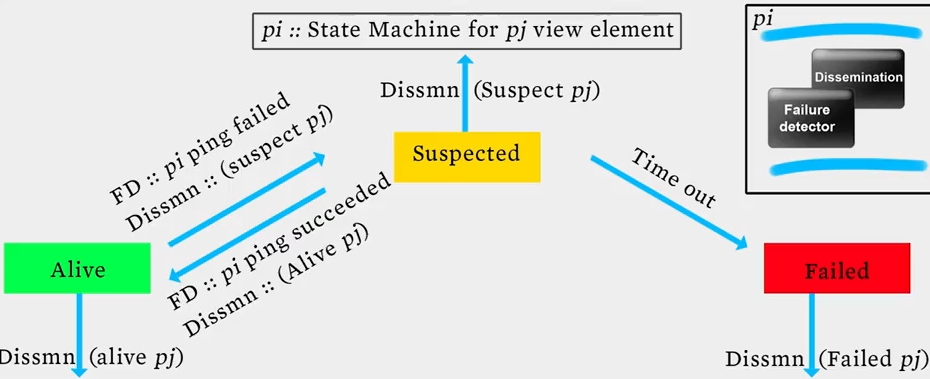
그림이 좀 복잡한데, 프로세스(노드) pi 기준으로 state 가 어떻게 변하는지를 나타낸 그림이라고 보면 됩니다. pj 에게 핑을 날려 응답하지 않으면 suspected 상태로 변하고, 여기서 timeout 되면 failed 되어 pj 가 failure 라고 dissemination 하는 상태가 됩니다.
한 가지 발생할 수 있는 문제점은 suspected 상태에서 alive 상태로 반복적으로 전환될 수 있다는 점입니다. 이러한 혼란을 피하기 위해 incarnation number 를 사용할 수 있습니다.
프로세스 pj 가 suspected 메세지를 받았을때, incarnation number 를 증가시킬 수 있는 것은 pj 만 가능합니다. 그리고 increase incarnation number 메시지를 받은 다른 프로세스들은 alive pj 메시지를 전달합니다.
높은 숫자의 incarnation number 가 더 우선합니다. 그리고 suspect 와 alive 같은 값이라면 suspect 메시지로 처리됩니다. 그리고 failed 메시지는 다른 어떤 메시지보다 더 높은 우선순위를 가지고 있습니다.
Summary
- failures the norm, not the exception in datacenters
- every distributed system uses a failure detector
- many distributed systems use a membership service
- ring failure detection underlies IBM SP2 and many other similar clusters
- Gossip-style failure detection underlies AWS EC2/S3 (rumored)
Refs
(1) Title Image
(2) Cloud Computing Concept 1 by Indranil Gupta, Coursera
comments powered by Disqus